Finite Tree Automaton とは
最近、プログラム合成の研究で Finite Tree Automaton (FTA、有限木オートマトン) を使った手法がいくつか見られる。このオートマトンはプログラムの集合を簡素に表現するために用いられる。プログラムの集合を簡素に表現する手法として、ちょっと前までは Version Space Algebra (VSA) がよく用いられていたが、ここ数年の流行りはボトムアップに構築する Finite Tree Automaton なのかもしれない。平成の VSA、令和の FTA。とは言ってもそんなに Finite Tree Automaton の論文の数が多いわけではないけど。
以下の3つの論文は Finite Tree Automaton を用いた合成手法である。
- Inductive Program Synthesis Over Noisy Data (ESEC/FSE 2020)
- Program Synthesis using Abstraction Refinement (POPL 2018)
- Synthesis of Data Completion Scripts using Finite Tree Automata (OOPSLA 2017)
本記事では、Finite Tree Automaton とそのプログラム合成への応用について簡単にまとめる。ただし図や表記は論文 Inductive Program Synthesis Over Noisy Data (ESEC/FSE 2020) からの引用である。
Finite Tree Automaton (FTA)
プログラム合成では Finite Tree Automaton の中でもボトムアップに状態を計算するものがよく見られるため、Bottom-Up Finite Tree Automaton を簡単に FTA と呼び、以降で解説することにする。ちなみに、日本語だと Tree Automaton は「木オートマトン」と訳されるっぽい。
一般的な有限オートマトンが文字列入力として状態を決定するのに対し、FTA は木構造を入力とするオートマトンである。具体的には、木構造を葉から根の方向へ順に読み込み状態を遷移させてゆく。根を読み込んだときの状態によって、その木が受理 (accept) されるか拒否 (reject) されるか決定するものである。
よりフォーマルに、 を言語とする FTA
を以下のように定義する。
は状態集合
(
) は受理状態 (accepting states)
は遷移関数であり、
かつ
として
という形をもつ。
なお、すべての は アリティ が定まっているものとする。たとえば、アリティが 0 である
は木構造の葉に対応する。ある入力
が受理されるとは、
に対して
の規則を適用すると
に遷移することである。
FTA の例として以下を考えてみる。
(アリティが 0 の言語)
(アリティが 1 の言語)
(アリティが 2 の言語)

このとき、木 によって状態がどのように遷移するのか考える。まず、木構造を以下に図示する。

この木に対して に含まれる規則をボトムアップに適用してゆくことで、木の頂点ごとに状態を定める。まず、木構造の根にアリティが 0 の規則を適用すると以下になる。

次に、規則 を適用する。

最後に、規則 を適用する。

結果として、木構造の根に対応する状態が となり、この入力は受理される。ちなみに、木構造をプログラムだと見なしたとき、このオートマトンは入力となるプログラムの評価結果が
になるもののみ受理するように設計されている。このように木構造を根からボトムアップに処理し、木全体に対して状態を1つの計算するのが FTA である。
Concrete Finite Tree Automata (CFTA)
ここからは入出力例からのプログラム合成でよく用いられるオートマトン Concrete Finite Tree Automata (CFTA) について説明する。
プログラム合成の問題では、プログラムを生成するための Domain-Specific Language (DSL) と、満たすべき入出力例
が与えられるのが一般的である。CFTA は、DSL
上で表現されるプログラムのうち、入出力例
を満たすプログラムのみを受理する FTA である。
CFTA の状態は、DSL の文法規則 と具体的な値
ごとに存在しうる。つまり状態を
と表現できる。状態
が存在するということは、与えられた入力値
のもとで、規則
を実行した結果として値
を実現する (部分的な) プログラムが存在する、という事実を表現している。さらに、DSL
の始記号を
、満たすべき出力値を
としたとき、状態
が存在することは、その合成が成功することを意味する。
CFTA の遷移関数は DSL の文法とその意味から導かれる。具体的には、DSL
の文法規則
に対して、その実行結果が
で与えられるとき、
遷移関数
が存在する。
CFTA の例として以下の DSL を考えてみる。

が始記号であり、
は入力変数、
は恒等関数である。つまり、入力変数
に 2 か 3 を足すか掛けるかしてできる式の集合を表している。
いま与えられた入出力例が であるとする。このとき、CFTA の一部は以下のようになる。入力値から実現できる値は無数にあるため「一部」しか図示できない。

ただし、状態は と具体的な値から構成されるため、
はひし形、
は円、
は長方形で具体的な値を囲むことで各状態が表現されている。たとえば、左の方の 1 を円で囲んだ状態は
を表している。本来、演算子
や
は2引数関数であるため、2つの状態を入力として1つの状態へ遷移するような図を書くべきであるが、2次元で上手く図示できないため、「
」や「
」など同じ状態が複数ヶ所に現れてしまっている。
CFTA の作り方は論文参照。ざっくり言うと、入力値 に対して DSL の演算を繰り返し適用することで、どの文法規則を適用した時点で何の値が得られるかを列挙できる。それを CFTA として表現するだけである。
CFTA とプログラム合成
DSL と入出力例から構成した CFTA を利用してプログラム合成の問題を解くことができる。具体的には、CFTA をグラフ構造として見たとき、初期状態に対応するノードから受理状態に対応するノードに至る経路上の文法規則を求めることで、入出力例を満たすプログラムを構成できる。
上記の CFTA の例では、初期状態の「ひし形の1」から受理状態の「二重円の9」に至る経路を求めればよい。たとえば、「」 ⇨「
」 ⇨「
」⇨「
」とたどることで、プログラム
を得ることできる。ちなみに経路が短いほどシンプルなプログラムが得られる。
このように合成の問題をグラフ構造の探索に帰着できることから、いくつかの CFTA の派生形が提案されている。
Inductive Program Synthesis Over Noisy Data (ESEC/FSE 2020) では、各ノードに重みをつけた State-weighted finite tree automata が提案されている。以下の赤字が各ノードに与えられた重みである。

さまざまな観点によって重みをつけることで、用途に応じた "よい" プログラムを優先的に合成できる。
Program Synthesis using Abstraction Refinement (POPL 2018) では、各状態が具体的な値ではなく "抽象的な値" に対応する abstract finite tree automata (AFTA) が提案されている。以下の AFTA の各状態は "抽象的な値" として値の範囲を示している。

AFTA を用いた合成アルゴリズムでは、シンプルな AFTA から始めて徐々に状態数を増やしてゆくことで、CFTA がもつ状態数の爆発的な増加を解決したものである。モデル検査において見られる abstraction refinement という考え方に着想を得ている。具体的な値の代わりに値を抽象的に表現するという点では抽象解釈 (abstract interpretation) に似ているともいえる。この論文はなかなか面白いのでいつか紹介記事を書きたい。
所感
- ボトムアップにプログラムを合成するアプローチとして、同じ入力に対して同じ出力を返すようなプログラムの集合を1つにまとめることを observational equivalence に基づくプログラムのクラスタリングと呼ぶことがある。おそらくこの処理は CFTA の構築と本質的に同じことをしているのだが、CFTA としてプログラム集合を表現しておくことでオートマトン同士の演算 (union, intersection) をしたり、合成の問題をグラフの探索問題に帰着したり、なにかと使い勝手がよいのだと思われる。
- にしてもこういう仕組みを考える人はすごい。オートマトンでプログラム集合を表現してみようとは思わない。言われてみれば難しい話ではないのだけど。
- プログラムの集合を表現する他のアプローチとして Version Space Algebra が存在する。いつかこっちの紹介記事も書いてみたい。
研究コミュニティ SyGuS について
今日はプログラム合成のコミュニティ SyGuS についての紹介。例によって日本で自分くらいしか興味がなさそうなトピック。そのうちきっと国内でも人気が高まるはず。。。
SyGuS とは
SyGuS はプログラム合成についての有力な研究コミュニティである。プログラム合成のソルバーを評価するためのベンチマークが登録されている StarExec には、2021年1月時点で289名のメンバーが登録されている。公式ページは以下である。
このコミュニティでは、プログラム合成の研究を活性化する取り組みが行われている。たとえば、プログラム合成の問題を共通的に記述するための言語 SyGuS Language を定義している。この言語で記述されたさまざまな問題がベンチマークとして公開されており、プログラム合成の手法の評価に活用できるようになっている。実際、プログラミング系のコミュニティの論文において、SyGuS のベンチマークを使用して手法の評価を行うのが定番となっている。
それに加えて、プログラム合成のソルバーの性能を競うコンペティションが毎年開催されている。 国際会議 CAV (International Conference on Computer-Aided Verification) の併設ワークショップとして SYNT Workshop が開催されており、そこでコンペティションが開催される。コンペティションにはいくつかのトラックがあり、2019年は以下の5つのトラックが設けられた。
- General SyGuS track (General),
- Invariant synthesis track (Inv),
- Conditional Linear Integer Arithmetic track (CLIA),
- Programming By Examples [Theory of Strings] track (PBE-Strings), and
- Programming By Examples [Theory of Bit Vectors] track (PBE-BV).
汎用的なソルバーを作ってすべてにエントリーしてもよいし、ドメインに特化したソルバーを作ってトラックを絞ってエントリーしてもよい。過去のコンペティションの結果は 公式サイト から参照できる。2020年はコンペティションが開催されていなかったが、2021年は 開催予定らしい。
問題の形式
SyGuS では、プログラム合成の問題が形式的に以下のように定義されている。
A Syntax-Guided Synthesis problem (SyGuS, in short) is specified with respect to a background theory
, such as Linear-Integer-Arithmetic (LIA), that fixes the types of variables, operations on types, and their interpretation. To synthesize a function
of a given type, the input consists of two constraints: (1) a semantic constraint given as a formula
built from symbols in theory
of expressions from
such that the formula
] is valid.
ざっくり要約すると以下のような感じである。
- 問題のドメインが指定され、許される型や演算子とその意味が定義される。
- 関数
- Syntax-Guided Synthesis problem (SyGuS) は、この2種類の制約を満たす関数
要するに、使える文法が固定された状況で、制約を満たすプログラムを見つけてね、って問題である。制約式を満たすプログラムの意味が一意に定まる問題もあれば、制約が曖昧であるため解が無数に存在する問題もある。
The SyGuS Language Standard
SyGuS の問題を記述するための言語 SyGuS Language が定義されている。この言語は SMT ソルバーの問題を記述する言語 SMT-LIB にインスパイアされている。
この言語を用いて記述した問題の例を以下に示す。この問題の正解となるプログラムは、2つの引数の最大値を返すような関数、いわゆる max 関数である。
;; The background theory is linear integer arithmetic
(set-logic LIA)
;; Name and signature of the function to be synthesized
(synth-fun max2 ((x Int) (y Int)) Int
;; Declare the non-terminals that would be used in the grammar
((I Int) (B Bool))
;; Define the grammar for allowed implementations of max2
((I Int (x y 0 1
(+ I I) (- I I)
(ite B I I)))
(B Bool ((and B B) (or B B) (not B)
(= I I) (<= I I) (>= I I))))
)
(declare-var x Int)
(declare-var y Int)
;; Define the semantic constraints on the function
(constraint (>= (max2 x y) x))
(constraint (>= (max2 x y) y))
(constraint (or (= x (max2 x y)) (= y (max2 x y))))
(check-synth)
ソースコードの引用元:https://sygus.org/language/
この例では、プログラムを構成するための文法が定義され、その後満たすべき制約が記述されている。文法では、整数型の変数の足し算や引き算、if-then-else 式などが許されている。意味的な制約としては3つの式が存在している。この制約を人間が書くくらいなら max 関数を人間が書いた方が早いというのはご愛嬌。
ちなみに、以下のプログラムがこの問題の解のひとつである。
(define-fun max2 ((x Int) (y Int)) Int (ite (>= x y) x y))
公開ベンチマークとソルバー
終了したコンペティションのベンチマークやソルバーは StarExec からダウンロード可能である。その他に、サンプルのソルバーや SyGuS Language 用のパーサーが Github 上で公開されている。
サンプルのソルバーの実行手順を以下にメモしておく。ソルバーは C++ で書かれているが、依存関係の問題でビルドに何度か失敗したので Docker のコンテナの中で環境を構築することにした。それにしてもビルドって行為がダルい。早く人類がビルドに悩まなくて良い時代が来てほしい。
Docker をインストールし、以下の内容を Dockerfile というファイル名で保存する。
FROM ubuntu:18.04 WORKDIR /root/sygus/ RUN apt update \ && apt install -y wget gcc \ && apt install -y make g++-4.8 git bison flex autoconf python \ && ln -f /usr/bin/g++-4.8 /usr/bin/g++ # boost setup RUN wget http://sourceforge.net/projects/boost/files/boost/1.57.0/boost_1_57_0.tar.bz2 \ && tar --bzip2 -xf boost_1_57_0.tar.bz2 \ && cd boost_1_57_0 \ && ./bootstrap.sh --with-libraries=program_options,system \ && ./b2 install -j4 --prefix=/usr \ && ldconfig # enumerativesolver RUN git clone https://github.com/rishabhs/sygus-comp14.git \ && cd sygus-comp14/solvers/enumerative/esolver-synth-lib \ && make -j4 RUN cp ~/sygus/sygus-comp14/solvers/enumerative/esolver-synth-lib/bin/debug/esolver-synthlib ~/sygus # stochastic solver RUN apt install -y libz3-dev libgmp-dev RUN cd ~/sygus/boost_1_57_0 \ && ./bootstrap.sh --with-libraries=regex \ && ./b2 install -j4 --prefix=/usr ## build parser RUN cd ~/sygus/sygus-comp14/parser/synthlib2parser/ \ && make -j4 \ && make opt -j4 ## build solver with appropriate configuration RUN cd ~/sygus/sygus-comp14/solvers/stochastic/stoch-SyGuS-14 \ && sed -i 's/..\/parser\/src\/include\//..\/..\/..\/parser\/synthlib2parser\/src\/include\//g' build \ && sed -i 's/..\/parser\/lib\/debug\//..\/..\/..\/parser\/synthlib2parser\/lib\/debug\//g' build \ && sed -i 's/..\/parser\/lib\/opt\//..\/..\/..\/parser\/synthlib2parser\/lib\/opt\//g' build \ && sed -i 's/clang++/# clang++/g' build \ && sed -i 's/echo "Clang done./# echo "Clang done./g' build \ && ./build RUN cd ~/sygus/sygus-comp14/solvers/stochastic/stoch-SyGuS-14 \ && mv a.out stochastic_solver \ && cp stochastic_solver ~/sygus/
Dockerfile のあるディレクトリで以下のコマンドを実行することで Docker イメージのビルドを行う。
おそらくビルドには数十分要する。
$ docker build -t sygus .
sygus という名前の Docker イメージが作成されたので、これを使ってコンテナを起動する。
$ docker run -it sygus
これでコンテナ上で動く ubuntu に入れる。ディレクトリには2種類のビルド済みのソルバーが存在する。
(公開されてるソルバーは3種類あったが、面倒なので2種類だけ頑張ってコンパイルした。)
root@3e23f40e5647:~/sygus# ls boost_1_57_0 boost_1_57_0.tar.bz2 esolver-synthlib stochastic_solver sygus-comp14
2種類のソルバーをそれぞれ実行してみる。
引数に与えた問題は2014年の SyGuS コンペの簡単な問題 (2引数の max 関数を合成する問題) である。
root@3e23f40e5647:~/sygus# ./esolver-synthlib sygus-comp14/benchmarks/integer-benchmarks/max2.sl Solution 0: (define-fun max2 ((x Int) (y Int)) Int (ite (<= x y) y x)) ----------------------------------------------- root@3e23f40e5647:~/sygus# ./stochastic_solver sygus-comp14/benchmarks/integer-benchmarks/max2.sl (define-fun max2 ((x0 Int) (x1 Int) ) Int (ite (>= x0 x1) (- x0 0) x1))
表現は異なるが、どちらも合成に成功していることが分かる。めでたし。
メモ
ソフトウェアコンポーネントの挙動をモデリングする手法
明けましておめでとうございます。
年末年始にいろいろ論文読んだので簡単にメモしてゆく。
タイトル
Modeling Black-Box Components with Probabilistic Synthesis
GPCE 2020
[2010.04811] Modeling Black-Box Components with Probabilistic Synthesis
https://dl.acm.org/doi/10.1145/3425898.3426952
概要
ソフトウェアコンポーネントのブラックボックスな振る舞いを模倣したプログラムを合成する手法。
手法の入出力
手法の入力
- 実行可能な関数 f(内部の構造は一切不明、つまり black-box とみなす)
- その関数のシグネチャ
出力の出力
- 実行可能な関数
- その振る舞いが入力の関数と(有限な入力において)等しい。
提案手法の手順
- 入出力データの生成
- 入力値は、元の関数の引数の型に応じて、固定された区間のランダム値を生成。
- ポインタ型の引数にはメモリブロックを割り当ててランダム値で埋める。
- 出力値は元の関数を実行して得る。
- 使用されそうな sketch の推定
- まず IID(Independent and Identically Distributed)に基づいて使用する fragments の推定
- 次に、Markov モデルで fragment sequence を推定
- sketch を LLVM IR のプログラムへコンパイル
- この時点ではプログラムは不完全であり実行できない(sketch がプログラムとして欠損しているため)
- プログラムの完全化
- basic block ごとに使用可能な SSA(single static assignment)変数を求める。
- それらを組み合わせて statements を構成する。この探索は enumerative search。
- 詳細は不明。組み合わせ爆発起こしそうだけどどうやって回避している?
疑問点メモ:
- もっともらしい sketch を見つけきてそれを完全化する流れは分かったが、もし sketch が不適切な場合はどういう手順になる?他の sketch にトライするみたいなアルゴリズムの設計になっていることは読み取れない。
確率モデル(Section 5)
2種類の確率モデル(IID, Markov)の部分が提案手法の特徴的な部分なので詳細を見てみる。
IID では、入出力データから使用されそうな fragment の集合を求める。ここで fragment とは合成のための DSL の要素のことである。fragment が組み合わされて1つのプログラムを構成する。詳細は Section 4 を参照。IID の学習には random forest モデルを使用しており、関数のシグネチャを入力として、それぞれの fragment を使用するかどうかを 1/0 で出力する分類器となっている。
Markov では fragment の列を予測する。このモデルの入力が何か読み取れない。関数のシグネチャとか入出力データを使う? 具体的には、学習データのプログラムを fragment の列とみなし、連続する2つの fragments を収集しカウントする。その割合をもとに fragments の列を生成することで sketch を構築する。ただし、前手順の IID で求めた fragments に含まれないものは除外する。fragments の終わりを示す特殊なトークンが出現するか、長さの上限に達したら sketch の構築を完了する。要するにトークン列の 2-gram の統計を利用してプログラムを生成するという感じ。
疑問点メモ:
- 学習データの詳細が不明。特に、学習データがなぜ fragment の列を持っているのか不明。合成を実現するための学習に、合成結果のプログラムを利用できる状況がよく分からない。あり得るとすれば、同じ DSL を使用する既存の合成エンジンがあるか、もっと素朴なやり方でこの DSL を使うプログラム合成エンジンを実装したか、くらいかな。まさか人手で大量のプログラムを作った?プログラムをランダムに生成する synthetic なやり方も考えたが、実際によく出現する 2-gram の統計を集めたい状況なので今回はこの方法はなさそう。
評価実験
既存研究のプログラム合成手法のために作られたベンチマークと、今回新たに集めた既存ライブラリの関数群を対象に実験を行った。これら合計112個のベンチマークの詳細は Section 7.3 を参照。
提案手法の入力としてプログラムが必要であるため、それぞれの問題にベンチマークに対して正解となるプログラムを C 言語で実装した。それぞれのプログラムから "適切" な数の入出力データを生成し、元のプログラムを復元できるかどうかを調べた。
その結果は以下の図の通り。提案手法 PRESYN が既存手法を outperform している。

提案手法があまりにも強すぎる。今回集めたライブラリだけでなく、先行研究のベンチマークでもすべての先行手法を上回っている。比較手法はどれも近年のトップカンファで発表されている手法なのに、なぜ提案手法の素朴なやり方でここまで outperform できるのか。一番怪しいのは確率モデルの overfitting。次点でベンチマークの作り方。
所感
- アイデアは面白い。black-box なプログラムを white-box なプログラムで近似するというアイデア。
- 提案した合成手法が、既存のあらゆる汎用的なプログラム合成手法を outperform しているのに、論文のタイトルは black-box なプログラムの挙動のモデリング。なぜ素直に、ノーヒントにも関わらず高い性能を持つ program synthesizer をタイトルにしなかったのか。しかも Section 1.1 を見ると program synthesizer の提案が contributions のほとんどを占めていてさらに気持ちが分からない。
- 機械学習モデルの精度は学習データに大きく左右されるが、この手法の IID と Markov モデルの学習の詳細が分からない。具体的に、どんな学習データでどのくらいの数のデータを学習に用いたのか読み取れない。ちなみにFigure 2 に training に関する図があるが、まさかの文中で参照されていないという。論文のフォーマットの規約に違反していそう。
- プログラムの sketch を完成させるための enumerative search の詳細が読み取れない。合成エンジンを提案する研究として、組み合わせ爆発の軽減はかなり肝な部分のはず。なぜ書かないのか。
記号実行とコンコリックテスト
記号実行(Symbolic Execution)とコンコリックテスト(Concolic Testing)は、プログラムの特定の箇所を通るような入力値を生成する手法であり、ソフトウェアテストに関する研究においてよく登場する。元々なんとなく理解していたつもりだが、もう少しちゃんと調べてまとめてみる。本記事では、まずは記号実行とコンコリックテストを説明し、それぞれの長所・短所を整理する。
これらの解説をググると「コンコリックテスト」と同じような意味で「コンコリック実行」という言葉が見られる。Wikipedia では Concolic Testing のページのみが存在しているので、本記事では「コンコリックテスト」という言葉を使うことにした。意味的に考えても、Concolic Testing は、対象のプログラムの実行と、プログラムに対する symbolic なインタプリタの実行を組み合わせているだけなので、「コンコリック実行」という実行をしているわけではないないよなぁ。専門家がどのくらい「コンコリック実行」という言葉を日常的に使うのかは知らないが。
背景
記号実行とコンコリックテストは、プログラムの「特定の箇所」を通るような入力値を生成する手法である。ソフトウェアテストの文脈では「特定の箇所」を「まだ通過していない箇所」として、そこを通る入力値を生成することで、たとえばカバレッジを向上するような入力値を生成できる。
ここで注意すべきは、よさそうな入力値を生成したからといって、あるべき出力値が分からないのであればテストとして成立しないということである。プログラムのあるべきふるまいは test oracle と呼ばれ、test oracle がテスト時に必ずしも分からない問題は test oracle problem と呼ばれている。一方で、ある値を入力したときに、プログラムがエラーを起こしてクラッシュするような場合はおそらく望ましい動作ではない。たとえば、組み込みシステムがメモリリークを起こす場合や、スマホアプリがエラーで落ちる場合などである。test oracle について詳しくは Wikipedia のページ を参照のこと。
記号実行やコンコリックテストは、このような暗黙的(implicit)な test oracle に違反する入力値を発見する手法である。 新たな入力値を生成し続けることで徐々にカバレッジを高めていき、その中でエラーを起こすような入力値が見つかればラッキーという感じである。
記号実行(Symbolic Execution)
記号実行の目的が分かったところで手法を具体的に説明する。前提として、記号実行は静的解析の手法であり、プログラムを実際に実行することなく具体的な入力値を生成する。
以下のソースコードを考えてみる。
1 void bar(int x, int y) { 2 z = 2 * y; 3 if (z == x) { 4 if (x > y+10) { 5 ERROR; 6 } 7 } 8 }
ソースコードの引用元:https://www.cs.cmu.edu/~aldrich/courses/17-355-19sp/notes/notes15-concolic-testing.pdf
このプログラムでは5行目でエラーを起こすため、ここを通るような入力値を生成できると嬉しい。入力値 x, yが与えられ、2行目で変数 y の値が2倍され、3, 4行目で条件式 z == x や x > y+10 によって分岐が行われる。5行目に到達するにはこれらの条件式を真にする必要があるが、その時に必要な入力値 x, y は何か?というのが解きたい問題である。
人間がじっくり考えれば5行目に到達する入力値を求められそうだが、コンピュータで機械的に計算するにはどうすればよいか?ここで登場するのが SMT ソルバーである。SMT ソルバーはざっくり言うと、論理式が満たせるかどうか判定し、満たす場合はその具体的な値を返すものである。今回のプログラムの例では、入力変数 x, y の具体的な入力値をそれぞれ ,
とすると、5行目に到達するには
という条件を満たす
,
が存在するかどうかを SMT ソルバーで解けばよい。その結果、SMT ソルバーがたとえば
という値を返すため、5行目に到達する具体的な入力値として x = 30, y = 15 という値を求めることができる。
ただし記号実行にはよく知られた課題がいくつかある。その一つとして、プログラム中の命令が SMT ソルバーの論理式として表現できないとき、適切な入力値を求められないことが挙げられる。たとえば、一般的な SMT ソルバーは値を足したり掛けたりする線形な演算をサポートしているものの、余りの計算や浮動小数点数の計算など非線形な演算はサポートしていない。そのため、目標とする箇所に至るまでにこれらの非線形な演算が含まれている場合、記号実行は役に立たない。
具体的には、以下のソースコードの場合は記号実行が上手く機能しない。
1 void bar(int x, int y) { 2 z = y * y % 50; 3 if (z == x) { 4 if (x > y+10) { 5 ERROR; 6 } 7 } 8 }
ほとんど先ほどのプログラムを同じであるが、2行目に非線形な演算(余りの計算)が含まれている。そのため、5行目に到達するための制約を SMT ソルバーで解ける論理式として表現できず、記号実行によって入力値を求めることができない。
プログラムでは表現できるが SMT ソルバーの制約としては表現できない。それなら、SMT ソルバーの制約として表現できない部分を、実際にプログラムを実行した結果で置き換えられないか?こんな発想から生まれたのがコンコリックテストである。
プログラムを読み込んで SMT ソルバーに与える論理式を作る処理はある種のインタプリタであるといえる。具体的には、プログラムの命令列を first-order logic の式として解釈するようなものである。プログラムと SMT が表現できる意味空間にミスマッチがあるため、記号実行が有効に働かない場合があるという状況である。
コンコリックテスト(Concolic Testing)
コンコリックテストは記号実行と動的解析を組み合わせた手法であり、プログラムを実際に実行しそのログを記録する必要がある。コンコリックテストの流れは以下である。(Wikipedia のページ より抜粋)
- 適当な入力値のもとでプログラムを実行し、その実行ログを記録する。
- 実行された経路に対して記号実行を行い、制約を論理式として構築する。論理式はプログラムの各命令と分岐条件を制約として表現したものである。
- 新たな分岐を通る入力値を求めるため、前手順で構築した論理式のうち分岐条件に対応するものを1つ選び、それを否定形で置換する。
- 構築した論理式を SMT ソルバーによって解き、新たな入力値を得る。この入力値が手順 1. とは異なる分岐を通過するものとなっている。新たな入力値が得られなければアルゴリズムを停止する。
- 新たな入力値のもとで手順1.へ戻る。
要するに、実際にプログラムを実行してみると入力値に対してどの経路が実行されるかを知ることができ、その情報からまだ通っていない分岐を通るような入力値を作り出す手法と言えそう。
コンコリックテストの具体的な実行過程を例を用いて説明する。
ここで記号実行が有効でないソースコードを再掲する。
1 void bar(int x, int y) { 2 z = y * y % 50; 3 if (z == x) { 4 if (x > y+10) { 5 ERROR; 6 } 7 } 8 }
まず、このプログラムにランダムな入力値を与えて実行し、どこを通るか観測する。たとえば、x = 22, y = 7 という入力値を生成して実行する。このとき、3行目の時点で z = 49, x = 22 となり条件式 z == x が偽になるため、エラーを起こす5行目には到達しない。ここで実際に通った経路に対して記号実行を行う。3行目が偽になるので という論理式が真になっているはずである。新たな分岐を通る入力値を生成するには、最後の条件式
の否定が真になるような制約式を考えればよい。つまり、
を満たす入力値を求めたい。しかし、非線形な演算(%)が含まれているのでこのままでは SMT ソルバーで解けない。ここで、入力値が y = 7 のとき3行目の時点で z = 49 となっていたことを利用すると、代わりに
を満たす
を求めればよいことが分かる。この解として
が求まり、x = 49, y = 7 という5行目のエラーを引き起こす入力値を求めることができる。
疑問点メモ:一般に、どのようなケースでコンコリックテストが有効に働くのか理解できていない。この例では入力変数として x と y の2つが存在していて、分岐条件 z == x の左辺 z は入力変数 y のみから決定され、右辺 x は入力変数 x のみから決定される。このように分岐条件が入力変数ごとに独立に決定される場合でコンコリックテストが有効に働くことは理解した。一方で、2行目が z = y * x % 50 であった場合は分岐条件 z == x の左辺 z は入力変数 x, y の両方によって決定される。そのため、実行時の zの値が具体的に分かったとしても z == x を真にする x の値を求めることは難しい(x の値を動かすと z の値が非線形に動いてしまうため)。入力変数が n 個存在する状況で、m コを具体的な値で固定したとき、残りの n-m コの取るべき値を線形的な制約から決定できるときにコンコリックテストが有効って感じ?
記号実行とコンコリックテストの比較
まず分かりやすい大きな違いは、記号実行は静的解析であり、コンコリックテストは動的解析の手法であることである。そのため、コンコリックテストの方が実行にコストがかかるし、そもそも実行ログを記録できない場合は使えない。
一方で、コンコリックテストの方が記号実行よりカバーできるプログラムの範囲が広い。具体的には、記号実行では対応できないが、コンコリックテストでは対応できる可能性のあるケースとして、以下のようものがある。
これは自分の理解に基づいたものであり、間違っているかもしれないので要注意。
- 非線形な演算や外部ライブラリの実行など、記号実行における制約式としてそもそも表現できないようなケース。コンコリックテストでは、記号実行できない演算をその具体的な実行結果で置換できる可能性があり、分岐条件を反転するような入力値を求めることができる可能性がある。
- 記号実行において SMT ソルバーの計算があまりに重いため具体的な入力値が1つも求められないようなケース。プログラムの複雑さによっては SMT ソルバーの計算が効率的に解けない状況が生まれるのは自然である。コンコリックテストでは、それらの実行の結果を具体的な値で置換することで、SMT ソルバーで解けるようになる可能性がある。
所感
- コンコリックテストは、記号実行で構築する論理式のうち SMT ソルバーで扱えない要素を、実際のプログラムの実行結果で置き換えることで、対応できる範囲を拡張するものであると理解した。論理式のうち SMT ソルバーが解釈できない部分はプログラム側で実行してあげて、SMT ソルバーが解釈できる形に置換して渡してあげるのがコンコリックテストの本質といえそう。解析対象のプログラムの意味を正確に再現できる最強のソルバーが存在する世界であればコンコリックテストは不要になるのかと思った。
- ググっていろいろ調べたが、記号実行で解けるプログラムの例を出してコンコリックテストの説明をしているものが多い。手法を説明するときは、その手法でしか解けないものを running example として例示してほしい。
- 本記事の途中でも書いたが、コンコリックテストが一般にどういう状況で有効に働くのか理解できていない。記号実行できない演算の出力を決定するために一部の入力変数の値を固定することで、残りの入力変数に対する制約を得て、それが SMT ソルバーで解ける場合はラッキー、という状況のはず。もし記号実行できない演算の出力がすべての入力値に依存するのであればコンコリックテストでも解けない、という理解であってるか?
たとえば、もっともシンプルな例として以下を考える。
1 void bar(int x) { 2 z = foo(x); 3 if (z == 10) { 4 ERROR; 5 } 6 }
記号実行できない演算 foo(x) があり、その出力が唯一の入力変数 x によって決定される。たとえば入力値として x = 3 を与えたとき z = 7 になったとして、意味のある制約式を SMT ソルバーに渡すことはできないはず。どんなときに foo(x) の出力が 10 になるのかを求めるのが本質的に難しいのだから。
一方で、以下のケースでは演算 foo() の結果は入力変数 x に依存しないので、コンコリックテストで意味のある入力値を見つけられる。foo() の具体的な値を入力変数 x に設定してやればよい。
1 void bar(int x) { 2 z = foo(); 3 if (z == x) { 4 ERROR; 5 } 6 }
この違いをちゃんと説明した文献とかないかなぁ。
参考文献
Symbolic execution - Wikipedia
https://www.cs.cmu.edu/~aldrich/courses/17-355-19sp/notes/notes15-concolic-testing.pdf
Kotlin の require, check, assert 関数の使い分け
いきなりまとめ
| 関数 | 用途 |
|---|---|
| require | 関数の引数のチェックに使う。 |
| check | 関数の引数以外のチェックに使う。 |
| assert | どこに使ってもよい。 実行時の VM 引数として -ea (-enableassertions) が必要。 |
背景
Kotlin には、引数として Boolean 型を取って、その引数が false であるときプログラムの実行を中止するような関数として require, check, assert の3つが存在する。本記事ではこれらの違いを述べる。 ついでにこれらの関数が何のために存在するのかも述べる。
"表明" という概念
プログラミングの重要な概念として「表明 (assertion)」という考え方がある。
ざっくり言うと、表明とは、プログラムの実行時に変数が満たすべき条件をコードとして表現することである。 たとえば「変数 i は負でない」とか「配列 a と配列 b の長さの合計は配列 c の長さに等しい」のような常に満たすべき条件をプログラムの一部として書く。成り立つべき条件を書いておけば、それが満たされない場合はエラーとして実行が中止されるため、以降の処理を安心して書ける。表明について Wikipedia のページ があるので詳しくはそれを参照のこと。
私はデバッグの用途で表明をよく使用する。 プログラムのあちこちに表明を書いておけば、バグの原因の切り分けが容易になることが多い。 また、ソースコード中になるべく "暗黙の前提" を残さないためにも、処理の節目に表明を入れておいたりする。こんな便利な表明であるが、Kotlin では表明に使用する関数として require, check, assert の3つがある。
それぞれの使い方を以下にまとめる。
require 関数
表明が満たされない場合 IllegalArgumentException が発生する。この例外は関数の引数が不正であることを示すためのものである。つまり、require 関数は、関数の引数に対する表明として用いるのが適切である。
require 関数の使用例は以下の通り。関数の引数である変数 count に対する表明を定義している。
fun getIndices(count: Int): List<Int> { require(count >= 0) { "Count must be non-negative, was $count" } // ... return List(count) { it + 1 } }
ソースコードの引用元: require - Kotlin Programming Language
ちなみにエラーメッセージ { "Count must be non-negative, was $count" } の部分はなくてもよい。その場合は IllegalArgumentException のデフォルトのメッセージが設定される。
念のため説明しておくと{ "Count must be non-negative, was $count" } というのは
fun require(value: Boolean, lazyMessage: () -> Any) の第二引数 lazyMessage に対応している。Kotlin では最後の引数が関数であるとき、中括弧 { } でくくったラムダ式を引数の外に出せる。
つまり、上記のソースコード中の
require(count >= 0) { "Count must be non-negative, was $count" }
は
require(count >= 0, { "Count must be non-negative, was $count" })
と同じ意味である。
check 関数
表明が満たされない場合 IllegalStateException が発生する。この例外は 、リクエストされた処理を実行するために適切な状態になっていないことを示すものである。関数の引数のチェックは require 関数を用いるとして、それ以外のチェックを check 関数で行うような使い方になる。
check 関数の使用例は以下の通り。引数でない変数 state に対する表明を定義している。
var someState: String? = null fun getStateValue(): String { val state = checkNotNull(someState) { "State must be set beforehand" } check(state.isNotEmpty()) { "State must be non-empty" } // ... return state }
ソースコードの引用元: check - Kotlin Programming Language
assert 関数
プログラムの実行時の VM 引数として -ea (-enableassertions) を与えたときのみ有効になる。Java の assert キーワードと同様に、表明が満たされない場合は AssertionError を発生させる。Java の assert と同じ立場を取るなら、どんな種類の表明に用いてもよいと言える。
ドキュメント:assert - Kotlin Programming Language
ソースコードの例としては、上記のソースコードの require 関数や check 関数を assert 関数に置換したものを考えればよい。
メモ
VM 引数でオン/オフが切り替えられる点において、assert 関数は require 関数や check 関数と少し毛色が異なる。そのため、表明の扱いに対するプロジェクトの方針として、以下の2通りのいずれかになることが多いのではないかと思う。知らんけど。
- require 関数と check 関数を使う
- assert 関数のみ使う
とにかく、表明という考え方は実用的なので、標準ライブラリとしてサポートしている Kotlin は素晴らしい。
真面目に JavaScript のクロージャを解説する
いつも備忘録ばかり書いているので、たまには世の中の駆け出しプログラマの為になるような記事を書きたい。
クロージャみたいなちょっとややこしい概念って、その意味を調べようと思ってググってもあまりよい資料が見当たらない。技術的なトピックを理解するのって「コアとなる考え方を正確に理解する」ことが重要だと思ってるのだが、多くの記事が「クロージャっぽさ」を説明してる感じで、読者としては「なんとなく理解できたがスッキリしない」みたいな気持ちになりそう。
本記事では JavaScript のクロージャについて割と正確に説明する。想定読者は、JavaScript の基本的な文法 (レキシカルスコープ や 第一級関数 を含む) は分かっているが、クロージャはよく分かっていないプログラマである。 例によって、このような水色の文字は補足的な内容であり読まなくてもよい。
環境 (Environment) とは?
まずは、クロージャの理解に重要な "環境" という考え方を説明します。 この "環境" という言葉は、辞書に載ってる普通名詞の意味でなく、プログラミング用語だと思った方がよいです。世の中のクロージャの解説記事を見ていると、この "環境" が何を意味するのか曖昧なものが多いように感じます。
突然ですが、ソースコード中に
console.log(x)
という文があったとき出力される値は何でしょうか?
答えはもちろん「分からないよ。出力される値は x の値に依存するからね。」といった感じです。
では、次の文ではどんな値が出力されるでしょうか?
console.log(x+y+z)
この場合も同様で「分からないよ。出力される値は x と y と zの値に依存するからね。」というのが正しいです。
では、x が 3、y が 2, z が 4 のとき console.log(x+y+z) は何を出力するでしょうか?
ここでようやく「9 が出力される」と値をユニークに答えることができるわけです。
ここまで当たり前のような話ですが、重要なポイントがあります。
それは「プログラムのふるまいはその時点での変数の値に依存する」ということです。
「x が 3、y が 2, z が 4 のとき」と書くのは冗長なので、簡単に {x:3, y:2, z:4} と書くことにします。
このような変数名と値のマッピングを 環境 (Environment) と呼ぶことにします。
プログラムのふるまいを知るには、実行される命令だけでなく環境を知る必要があるということです。
なお、環境はプログラムの実行が進むにつれて内容が更新されます。
たとえば、以下にソースコードと、各行の実行が終わったときの環境をコメントとして記載しています。
function f() { var x = 3; // {x:3} var y = 2; // {x:3, y:2} var z = 4; // {x:3, y:2, z:4} x = 8; // {x:8, y:2, z:4} console.log(x, y, z); }
新たな変数が定義されたり、すでに存在する変数の値が更新される場合などは環境が更新されます。
環境 (Environment) という考え方はコンピュータサイエンスとしては一般的なものであり、たとえば SICP の 3.2 章 に載っていたりします。他には、インタプリタを実装するときによく登場する用語です。プログラムを interpret するというのは、プログラムをその environment において評価する行為に他ならないので。
関数の入れ子と環境
次は、2つの関数が入れ子になっている、つまり関数の中に関数が定義されているときの環境について見てみます。
以下のソースコードでは2つの関数 parent と child が入れ子になっています。
関数 parent が実行されるときの各行の実行後の環境をコメントとして記載しています。
function parent() { var a = "hello"; // {a:"hello"} var b = "world"; // {a:"hello", b:"world"} function child() { var x = 3; // {x:3} var y = 2; // {x:3, y:2} var z = 4; // {x:3, y:2, z:4} console.log(a, b, x, y, z); } child(); }
ここで押さえてほしいポイントは 「環境は関数の実行 (呼び出し) ごとに生成される」 ということです。
この例では関数 parent と child それぞれが1回ずつ実行されるので、parent と child のそれぞれに対応する環境が生成されています。
実は、上のソースコードで示した環境には誤りがあります。
変数のスコープの考え方を知っていればその誤りに気付けるのですが、関数 child の中でも parent 内で定義された変数 a, b の値が見えているべきです。
ここで2つ目のポイントなのですが 「関数の定義が入れ子になっているとき、子の環境は親の環境にアクセスできる」ということです。
具体的には、環境を以下のように考えるのが正しいです。
function parent() { var a = "hello"; // {a:"hello"} var b = "world"; // {a:"hello", b:"world"} function child() { var x = 3; // {x:3, a:"hello", b:"world"} var y = 2; // {x:3, y:2, a:"hello", b:"world"} var z = 4; // {x:3, y:2, z:4, a:"hello", b:"world"} console.log(a, b, x, y, z); } child(); }
今回は child の環境の中に、parent の環境 {a:"hello", b:"world"} の内容が含まれています。
子の関数の実行時に親の環境が見えているということです。
クロージャとは?
いよいよクロージャについて説明します。ここまでの話が理解できていれば後は簡単です。
関数の入れ子と環境について重要なポイントは (A) 子の関数の実行時に作成される環境が、 (B) 親の環境 (子の関数を定義している環境) へアクセスできることでした。
特に興味深いのが、(A) の子の関数が (B) の親の関数に返り値として返される場合です。
具体的には以下のソースコードのようなケースです。
function parent() { var a = "hello"; var b = "world"; function child() { var x = 3; var y = 2; var z = 4; console.log(a, b, x, y, z); } return child; }
このソースコードは関数定義をしているだけであり、まだ関数 parent も child も実行されていないので、環境は生成されていません。これらの関数を実行するときに環境がどうなるか見ていきます。
関数 parent を実行します。
var ch = parent()
すると、実行後には親の環境として {a:"hello", b:"world"} が生成されます。 この時点では子の関数 child は実行されていないので、child に対応する環境は存在していません。
つぎに、子の関数 child を実行します。関数 parent から返された関数 ch を実行するだけです。
ch();
すると、子の環境が生成され、実行後には {x:3, y:2, z:4, a:"hello", b:"world"} となります。
前述したポイントである「子の関数の実行時に生成される環境は、親の環境 (子の関数を定義している環境) へアクセスできる」ことにより、子の環境が親の環境 {a:"hello", b:"world"} を含んでいるのが肝です。
この状況って少し違和感がありませんか?
親だった関数 parent の実行が終わっているのに親の環境は残り続けていて、その環境に、変数 ch として返された関数がアクセスできるって状況なのですよ。
つまり、変数 ch は、自身の正体が関数 child であることだけでなく、親の環境 (関数 child を定義している環境) を知っているということです。
実は、このような「親の環境」の情報をもつ関数こそが "クロージャ" です。
今回の例では 変数 ch (つまり関数 parent の返り値) がクロージャになっているということです。
なお、クロージャという言葉には "閉じ込める" というニュアンスがあります。クロージャは、親の環境を "閉じ込め" て、その子の関数のみがアクセスできる状態を作り出す技術です。
図で理解するクロージャ
ここまで言葉でクロージャを説明したのですが、図を使って状況を整理してみましょう。 使用するソースコードは先ほどと同じです。
function parent() { var a = "hello"; var b = "world"; function child() { var x = 3; var y = 2; var z = 4; console.log(a, b, x, y, z); } return child; }
まずは、関数の定義が入れ子になっていることを以下のように表してみます。
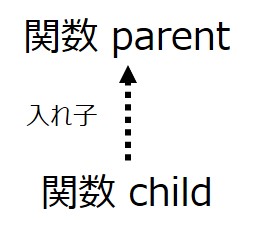
なにも複雑なことはありません。この図は関数の実行結果など関係なく、ただソースコード上で関数が入れ子に定義されているという事実を示しています。
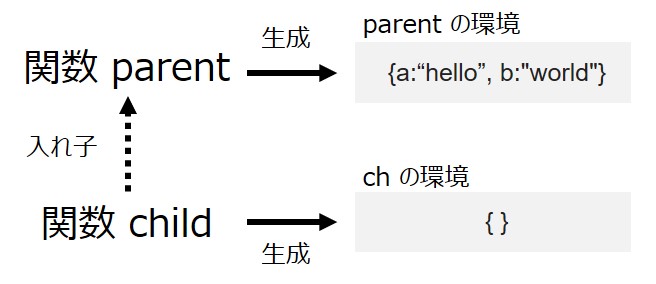
つぎに、関数 parent を実行します。
var ch = parent()
このとき、関数 parent が実行されるので、対応する環境が生成されるはずです。
この様子を以下のように表してみます。

そして、子の関数 ch を呼び出しします。
ch();
その結果は以下のような図になります。関数 ch が呼び出された瞬間は ch の環境は空っぽです。
このタイミングこそが、クロージャが仕事をする瞬間です。
関数 ch はクロージャなので、子の関数の環境が生成されたとき、子の環境が親の環境にアクセスできるのがポイントです。図を書くと以下のようになります。
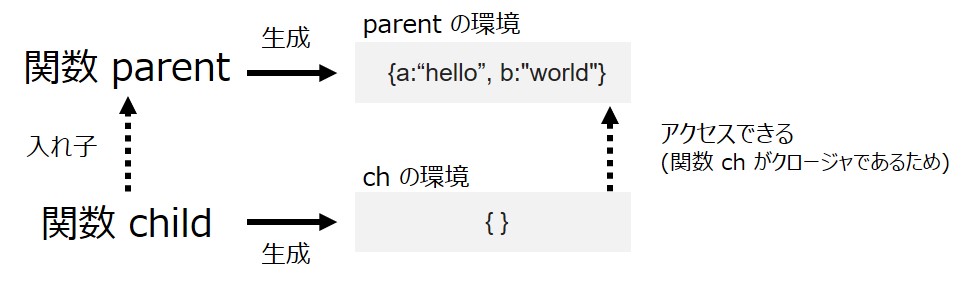
このような流れで、関数 ch の実行時に親の環境に存在する変数 a や b を使用できるわけです。
一方で、親の環境を "閉じ込める" のがクロージャでした。関数 parent の子でない関数 f や g があったとしても、それらは「parent の環境」へアクセスできません。図を書くとこんな感じでしょうか。
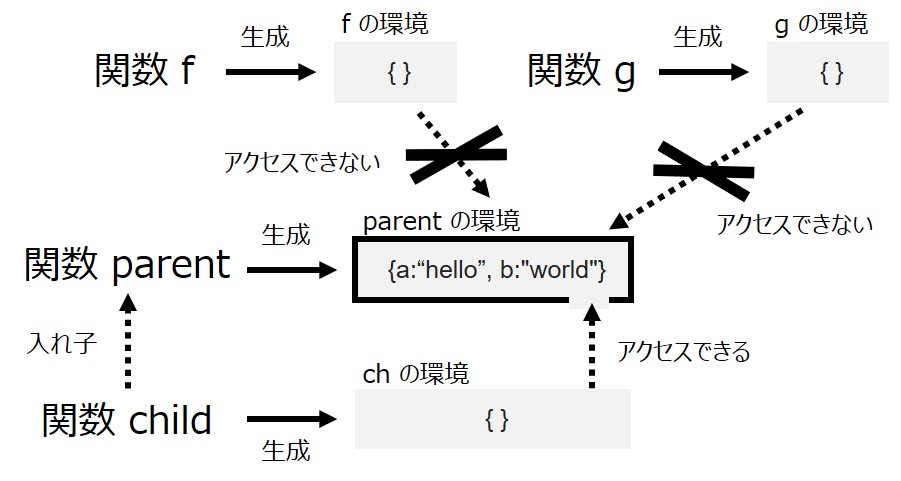
クロージャのなにが嬉しいのか?
クロージャの利点は、関数の外部から隠蔽した状態、つまり private な変数を実現できることです。
Java などのオブジェクト指向のプログラミング言語に触れたことがあれば、クラスの外部から直接操作されない private なフィールドは、高い保守性をもつ設計に欠かせないものであることをご存知だと思います。
カウンタの例 (inc のみ)
クロージャの説明としてありがちなカウンタの例を考えてみましょう。
以下のソースコードを考えます。
function counter() { var cnt = 0; // 変数 cnt は関数の外からはアクセスできない(private になっている) function inc() { cnt++; return cnt; } return inc; };
関数 counter と関数 inc が入れ子に定義されています。
親の関数 counter で変数 cnt が定義されていて、これを子の関数 inc 内でインクリメントしています。
ここで関数 counter を2回実行し、それぞれによって返された関数 a, b を適当に実行してみます。
var a = counter(); var b = counter(); a(); // => 1 a(); // => 2 b(); // => 1 a(); // => 3 b(); // => 2
コメントとして実行結果を書いているのですが、a と b はそれぞれ独立にカウントアップすることが分かります。 関数 a, b それぞれが自身の状態 (変数 cnt の値) を管理しており、外部からは書き換えられない安全な設計になっているのがポイントです。
図に書いてみると状況が分かりやすいと思います。
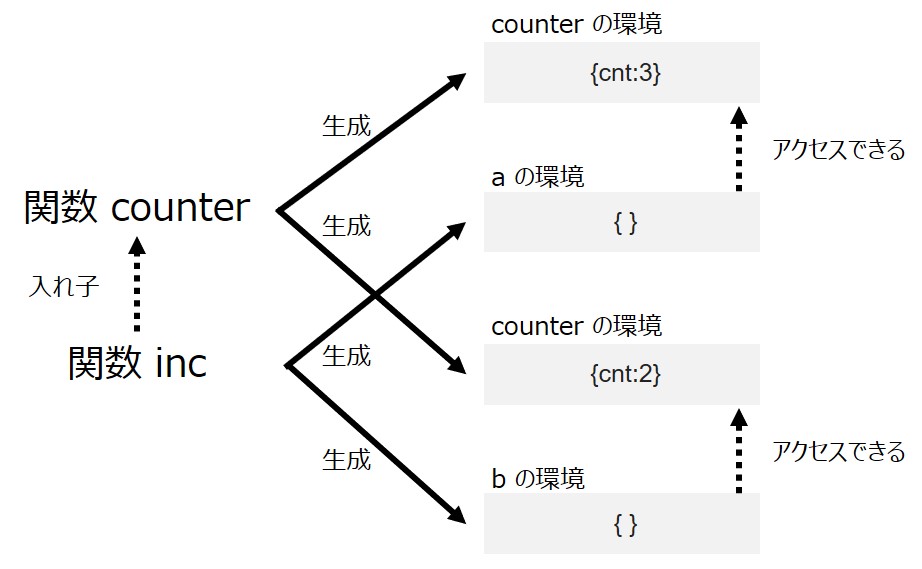
ソースコードでは counter(); の実行が2回行われるので、それぞれのタイミングで「counter の環境」が生成され、関数 a と b の実行時にはそれぞれ異なる「counter の環境」にアクセスできるというわけです。
また、「counter の環境」へのアクセスは関数 counter 内で定義されている関数のみ (今回は関数 inc のみ) に許されており、外部からの書き換えを保護しています。
カウンタの例 (inc, dec)
つぎは、カウントアップとカウントダウンを許すカウンタを考えてみましょう。
以下のソースコードを見てみます。
function counter() { var cnt = 0; function inc() { cnt++; return cnt; } function dec() { cnt--; return cnt; } return { inc: inc, dec: dec, }; }; var c = counter(); c.inc(); // => 1 c.inc(); // => 2 c.inc(); // => 3 c.dec(); // => 2 c.dec(); // => 1 c.inc(); // => 2
今回のポイントは、関数 counter 内で関数 inc と dec が定義されているうえに、両方の関数が返り値として返却されているところです。
この状況では、関数 inc と dec がともに 同じ親の環境を共有する クロージャになっています。
それでは図を見てみましょう。
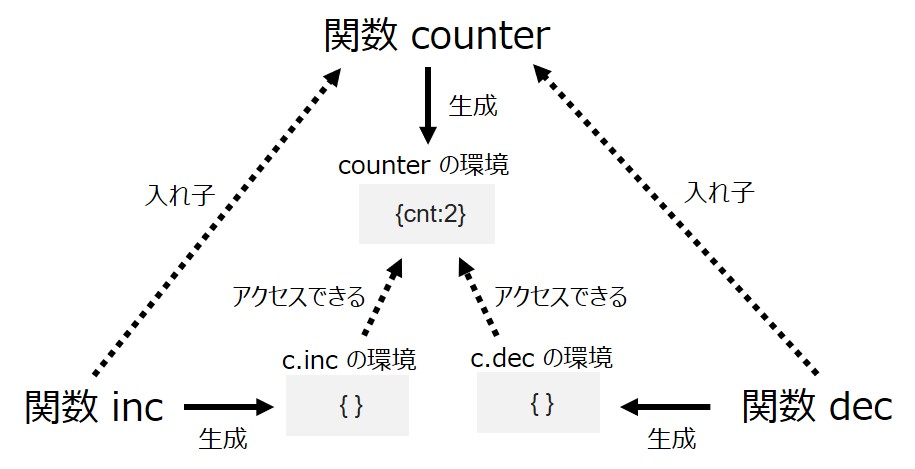
なかなか複雑になってしまいましたが、c.inc と c.dec の実行が同じ「counter の環境」を共有していることが分かります。そのため、関数 c.inc と c.dec は独立にふるまうのではなく、それぞれの関数の実行結果を互いに反映します。
これはまさにオブジェクト指向における private なクラスフィールドとメソッドのような関係です。
まとめ
クロージャは、関数が入れ子で定義されているときに出現する、親の環境についての情報をもつ関数のことです。
JavaScript 上で、オブジェクト指向でいう private フィールドを実現するための仕組みとも言えます。
説明がややこしくなるのでこの記事では言及していなかったのですが、JavaScript はトップレベル (どの関数にも属さない範囲) にも環境をもっています。これはいわばグローバルな環境であり、グローバル変数はここに属します。そういう意味では、入れ子になっていない関数もグローバルな環境へアクセスできるクロージャであると言えます。この場合、親の環境がグローバルなので、クロージャの利点である「外部からの直接的な状態の変更を保護する」ような役割は顕在化しまん。したがって、入れ子になっていない関数がクロージャであることを意識する必要はまずないと思います。一方で、このような事情から「JavaScript の任意の関数はクロージャである」と言われるのは理論的には正しいです。
思ったより説明が長くなって疲れたのですが、駆け出しプログラマの理解の助けになれば幸いです。
参考文献
Datalog に入門する
とある論文がデータのスキーマ変換を行うために Datalog を用いていた。Prolog は触ったことあるし、Datalog って言葉も聞いたことはあったが、具体的にどんな言語で何が嬉しいのか知らなかったのでちょっと調べてみた。
ついでに Datalog のインプリタとして Soufflé という処理系も触ってみた。
Datalog とは
- Datalog は、論理型プログラミング言語である Prolog のサブセットであり、主に演繹データベースのクエリ言語として用いられる。クエリは論理的な制約として記述され、その制約を満たすデータをデータベースから抽出する。最近では Datomic のような分散データベースのクエリ言語としても用いられている。
- Datalog として標準化された言語が言語仕様があるわけではなく、処理系によって構文が異なっていたり、独自の拡張がされていたりする。たとえば、集約関数をサポートするものなどがある。
- 一般に Datalog の表現力は Prolog より制限されたものであり、チューリング完全ではない。この制限がクエリの効率的な実行(推論)を実現している。また、Datalog は完全に宣言的な言語であるといえる。つまり、記述された命令の順序に意味はない。
- Datalog を用いたクエリは first-order logic を用いて記述される。また、Datalog のプログラムを構成する要素として extensional predicate (事実の集合、facts と呼ばれる) と intensional predicate (事実から事実を導くルール, rules と呼ばれる) がある。
- たとえば、データベースの中身は facts であり、抽出したいデータの集合も facts である。このときクエリは rules として記述され、データベースの facts から抽出したいデータの fatcs を導出するものであるといえる。
ここまでのメモ。
- facts から facts へ変換するルールを rules として記述するだけなので、データベースへの問い合わせだけでなく、異なるスキーマをもつデータ間の変換の操作を Datalog を用いて表現できる。これが Datalog がさまざまなドメインで利用されている背景と言えそう。
Soufflé とは
Datalog の雰囲気が分かったところで、具体的な処理系である Soufflé を触ってみる。公式サイトは以下。
Soufflé は、もともとは Oracle Labs でプログラムの静的解析用に開発されたツールであるが、今ではデータ分析などさまざまな領域において利用されている。ソースコードは Github 上で公開されており、2020年現在もメンテナンスが行われている。ひとつの特徴として、Datalog プログラムを C++ へのトランスパイルが可能であることが挙げられる。これによって、マルチコアなど最新の計算資源を活用したプログラムを書けるのが強みである。
Soufflé のインストール
インストール手順は公式ページにある通り。
Install Soufflé | Soufflé • A Datalog Synthesis Tool for Static Analysis
使っている OS が Ubuntu 20.04.1 LTS (Focal Fossa) なので、apt のためのリポジトリの指定時に bionic の代わりに focal を指定した。
Datalog プログラムの例
以下の公式ページに載っている Datalog プログラムの例を見てみる。
なお本記事に記載するすべてのソースコードは公式ページからの引用である。
Examples | Soufflé • A Datalog Synthesis Tool for Static Analysis
今回のプログラムは、手続き型言語のポインタ解析を行うシンプルな例である。具体的には、変数のフィールドやエイリアスは考慮するが、制御フローは考慮していない。ちゃんと言うと field-sensitive かつ flow-insensitive な Points-to analysis になっている。
ソースコードを上から順に見てゆく。
今回の解析対象の手続き型のプログラムの構造は以下である。
// Encoded code fragment: // // v1 = h1(); // v2 = h2(); // v1 = v2; // v3 = h3(); // v1.f = v3; // v4 = v1.f; //
変数として v1, v2, v3, v4 の4つ、オブジェクトとして h1, h2, h3 の3つがある。このポインタ解析では各変数が指しうるオブジェクトの集合を求める。答えから言ってしまうと、今回のポインタ解析では
変数 v1 はオブジェクト h1 または h2 を指し、v2 は h2, v3 は h3, v4 は h3 を指しうる、という結果になる。
ちなみに、本当は変数 v1 は h2 しか指さないのだが、制御フローを考慮していないので、h1 を指しうると誤検知している。静的解析は安全側に倒す(つまり真の解より広めの範囲を返す)のが一般的であるためこういうことになっている。
次に独自の型を定義している。symbol というのは文字列型だと思っていればよさそう。変数 var、オブジェクト obj、フィールド field がそれぞれ文字列により一意に定められるということ。
.type var <: symbol .type obj <: symbol .type field <: symbol
ここから facts を与えてゆく。
まずは4つの関係 (relation) を定義する。このような "関係" という考え方は Prolog と同様であり、データ間に成り立つ事実であると思えばよい。たとえば、assign( a:var, b:var ) は「変数 a が、変数 b の指すオブジェクトを指す」という a と b の2項関係である。
// -- inputs -- .decl assign( a:var, b:var ) .decl new( v:var, o:obj ) .decl ld( a:var, b:var, f:field ) .decl st( a:var, f:field, b:var )
そして facts を具体的に与えてゆく。与える facts は解析対象のプログラムに対応している。たとえば、プログラム中で変数 v2 が v1 に代入されているので、assign("v1","v2") が与えられる。
// -- facts -- assign("v1","v2"). new("v1","h1"). new("v2","h2"). new("v3","h3"). st("v1","f","v3"). ld("v4","v1","f").
ここから最終的に求めたいポインタ解析の結果を導くための rules を定義してゆく。
以下は、エイリアス関係を表現するための alias( a:var, b:var ) である。
// -- analysis -- .decl alias( a:var, b:var ) alias(X,X) :- assign(X,_). alias(X,X) :- assign(_,X). alias(X,Y) :- assign(X,Y). alias(X,Y) :- ld(X,A,F), alias(A,B), st(B,F,Y).
変数 a と b がエイリアスの関係にあるのは、4通りのパターンがあることが分かる。
1つ目の alias(X,X) :- assign(X,_). という rule であるが、これは「代入文の左辺に登場する変数はその変数自身とエイリアスの関係にある」という当たり前のケースである。2つ目のケースも同様である。
3つ目の alias(X,Y) :- assign(X,Y). では「代入文があれば左辺の変数は右辺の変数のエイリアスになる」という rule である。
4つ目の alias(X,Y) :- ld(X,A,F), alias(A,B), st(B,F,Y). がやや複雑なケースであり、変数 A, B がエイリアスであり、X = A.F と B.F = Y という代入があるとき、変数 X, Y がエイリアスになるという rule である。
最後に、ポインタ解析の結果となる pointsTo( a:var, o:obj ) という関係を定義する。
.decl pointsTo( a:var, o:obj ) .output pointsTo pointsTo(X,Y) :- new(X,Y). pointsTo(X,Y) :- alias(X,Z), pointsTo(Z,Y).
この rules はシンプルであり、new した場合と、エイリアスの変数が指しうるオブジェクトを自身も指しうる場合の2つからなる。
この関係が最終的に求めたいものであるので、.output pointsTo という命令を書くことで pointsTo.csv というファイルに結果が出力される。以下がその例である。各行が fact になっており、変数とそれが指しうるオブジェクトを意味している。
$ cat pointsTo.csv v1 h1 v1 h2 v2 h2 v3 h3 v4 h3
このポインタ解析の例では、「どうやって指しうるポインタを求めるか?」というアルゴリズム的な視点が不要であり「どんな関係が成り立つか?」を定義するだけでよい。これが Datalog のような論理型のプログラミング言語の利点である。実際、この程度のポインタ解析でも非論理型のプログラミング言語で実装するのはけっこうめんどくさい。
その他 Soufflé について
上記は簡単な例であったが、チュートリアル を進めていくと Soufflé のより高度な機能について知ることができた。あとは何か実装したくなったら調べながらやればよさそう。以下は Soufflé に関するメモ。
- 入出力となる facts はcsv だけでなく SQLite3 データベースにも対応している。つまり、RDB に対するクエリとして使用したり、結果を RDB のテーブルとして格納できる。これは便利そう。
- チュートリアルの中に、集合
Aの要素の順序関係を示すSucc(x:symbol, y:symbol)という関係があったが、これを使って順序の先頭First(x: symbol)を表現するのに悩んだ。答えはFirst(x) :- A(x), ! Succ(_, x).である。を求めればよいと思ったが、これを
と変形して、
の部分を Datalog の
_で置換するのが正しい。このあたりは Prolog らしい部分であり、慣れが必要そう。 - Prolog のクエリとしてよくある
?:-parnt(X, Y)みたいな形式は Soufflé ではサポートされてないっぽい。インタラクティブな使い方より、ファイルを入出力とするバッチ処理的な用途が想定されていそう。