【OS自作】littleosbook をやってみる #2
前回に続き、OS 自作のチュートリアル littleosbook の続きをやっていく。前回の内容は以下。
littleosbook は以下。今回は4章から。
追記:本家の littleosbook は不備が多いがメンテナンスされてない。以下はフォークされたリポジトリであり、かなりの不備が修正されている。絶対こっち見るほうがオススメ。
4 Output
この章では、カーネルとハードウェアをつなぐドライバを作る。前半は、コンソール上にテキストを表示する framebuffer のドライバを作る。後半は、シリアルポートのドライバを作る。Bochs ではシリアルポートからの出力をファイルに保存できるので、OS 開発のロギングのために使用するとのこと。
4.1 Interacting with the Hardware
ハードウェアとやりとりするには memory-mapped I/O と I/O ports の2通りある。memory-mapped I/O では特定のアドレスのメモリに書き込むだけでハードウェアの挙動が更新される。I/O ports を用いた場合は out 命令や in 命令を使ってハードウェアとやりとりする。ソケット通信のような感じ。
4.2 The Framebuffer
framebuffer は、メモリの内容をスクリーンの描画するデバイスである。
4.2.1 Writing Text
framebuffer は memory-mapped I/O であり、0x000B8000 番地から始まるメモリ領域に値を書き込むとコンソールにテキストを書き込めるらしい。
たとえば、A という文字を緑色の文字で灰色の背景色で表示したかったら以下のように mov すればよいとのこと。
mov [0x000B8000], 0x4128
しかし、error: operation size not specified のようなエラーが出てアセンブリのコンパイルが通らない。調べたところ、mov 命令するときにサイズの指定が 必要らしい。今回は2バイトなので word を指定してみる。
mov word [0x000B8000], 0x4128
コンパイラは通るようになったが、( という文字が赤色の背景に青文字で表示されてしまう。記載されているメモリのバイトと色などの対応がおかしいと思われる。いろいろ調べた結果、代わりに以下のページの Text buffer のレイアウトに従うと意図通りに A が表示されるようになった。
チュートリアルに記載されているものと Wikipedia のものが全然違う。この違いがどこから来ているのかは不明。とりあえず自分の環境では Wikipedia のものを参考にするのが正しそう。ちょっと遊んでみると、Hello と表示したかったら以下のようにアセンブリコードを書けばよい。
mov word [0x000B8000], 0x4248 ; H mov word [0x000B8002], 0x4265 ; e mov word [0x000B8004], 0x426C ; l mov word [0x000B8006], 0x426C ; l mov word [0x000B8008], 0x426F ; o
各 mov 命令が2バイトの値を代入しているので、次の文字を表示するための番地も2ずつ増やしている。なぜかチュートリアルでは次のセルに行くには16増やさないといけないと書いている。なぜなんだ。実行結果は以下のようになる。先頭から Hello の文字列を表示できた。

ここからは、以上の動作を C プログラムとして書いておくことで便利にしようというもの。上記で述べた不整合があるので、それを考慮して直した C コードは以下。動作確認のため kmain 関数内で Hello を描画するようにしてみた。
#define LIGHTGREEN 0x0A #define BLACK 0x00 char *fb = (char *)0x000B8000; void fb_write_cell(unsigned int i, char c, unsigned char fg, unsigned char bg) { fb[i] = c; fb[i + 1] = ((bg & 0x0F) << 4) | (fg & 0x0F); } void kmain() { fb_write_cell(0, 'H', LIGHTGREEN, BLACK); fb_write_cell(2, 'e', LIGHTGREEN, BLACK); fb_write_cell(4, 'l', LIGHTGREEN, BLACK); fb_write_cell(6, 'l', LIGHTGREEN, BLACK); fb_write_cell(8, 'o', LIGHTGREEN, BLACK); }
アセンブリからは以下のように呼び出せる。チュートリアルでは external 命令を使うと書いているが extern を使うのが正しいっぽい。
extern kmain call kmain
ここまでバグ修正しながら頑張ってきたが、よく見ると同様の修正のプルリクエストが上がっていた。やっぱ自分の環境の問題じゃないのかなぁ。
4.2.2 Moving the Cursor
ここからはカーソルを動かす話。I/O ports を使ってカーソルの位置をハードウェアに送信する。カーソルの位置は2バイトで指定されるので、上位1バイトと下位1バイトを分けて送信する必要がある。上位であるか下位であるかは 0x3D4 ポートに 14 or 15 を送信を送信することで表明し、実際のデータは 0x3D5 ポートに送信する。
手順通りに進めれば C プログラムからカーソルの位置を指定できるようになった。ただし、途中で undefined reference to outb みたいなエラーメッセージが出て make run できなかった。以下の issue を参考に Makefile を修正すると直った。ld コマンドのためのオブジェクトが足りていなかったみたい。
4.2.3 The Driver
fb_write_cell 関数で1文字ずつスクリーンに文字を表示させるのは面倒なので、文字列をまとめて表示する write 関数を作るのがよいとのこと。
その通りに自分で C コードを書いてみたがどうも上手くいかない。具体的には、C コードの中で文字列リテラルを使うとコンパイルは通るが、Bochs を起動すると Error 13: Invalid or unsupported executable format のようなエラーが出る。困った。
いろいろ調べてみると同じ問題に遭遇している人がいた。
問題としては、loader.s の section .text: というセグメント定義のコロンが不要らしい。正しくは section .text で text セグメントを定義できる。このエラーが、文字列リテラルを格納する rodata セグメントに影響を与えていたらしく、文字列リテラルを使ったときだけエラーが出るようになるとのこと。よく見ると issue としてこの問題を報告しているものもあった。はやく本家が直してくれ、無駄に時間が溶ける...。
結果として、以下の write 関数を実装してみた。表示の開始位置(cursor)は今のところ適当にしている。表示する文字数は関数の引数から外し、常に引数の文字列すべてを表示するようにしている。
unsigned int cursor = 0; void write(char *buf) { for (unsigned int i = 0; buf[i] != '\0'; i++) { fb_write_cell(cursor + i * 2, buf[i], LIGHTGREEN, BLACK); } }
4.3 The Serial Ports
serial ports はハードウェア同士を接続するためのインターフェースである。serial ports の制御は I/O ports を介して行われる。つまり、I/O ports の特定のポートにデータをいろいろ送りつければ、serial ports を使えるということだと思われる。このチュートリアルの記述だけではシリアルポートの意味がよく分からなかったので、以下の OSDev Wiki のページを見てみた。
Bochs などのエミュレータがシリアルポートの出力をホストマシンに標準出力やファイルで伝達できることから、OS 開発においてシリアルポートがよく使われるとのこと。COM1, COM2,... などの COM ports というのは serial ports のことを指していると思ったらよさそう。COM1 を使うとして、COM1 の 0x3F8 ポートにオフセットを指定すると、各種データを設定するためのポートになる。たとえば、オフセットとして +3 を指定すると「Line Control Register」であり、このポートに設定値を送りつけると通信の設定ができる。
4.3.1 Configuring the Serial Port
2つのハードウェアを通信するには通信の設定を揃える必要があり、そのための設定値を送る必要がある。設定の例として bit rate, parity bit, data units の3つが挙げられている。これらの値をこれから設定してゆく。
4.3.2 Configuring the Line
ここではデータ送信の速度を示す bit rate を設定する。serial port ごとに line command port というのがあって、これは COM1 のようなベースとなるポートに +3 すれば求まる。速度の設定は 115200 Hz を割る値を 16 bits で指定し、data port(これはベースとなるポートと同じ)に送ればよい。ただし data port には 8 bits ずつしか送れないので、前半と後半の1バイトずつに分けて送る。
4.3.3 Configuring the Buffers
serial port を介した通信のバッファについての設定。以下のように 0xC7 を設定してみた。
void serial_configure_FIFO(unsigned short com) { outb(SERIAL_FIFO_COMMAND_PORT(com), 0xC7); }
4.3.4 Configuring the Modem
モデムの設定。これは何を設定しているのかよく分からんが、以下のようなコードを書けばよいことは分かった。
void serial_configure_modem(unsigned short com) { outb(SERIAL_MODEM_COMMAND_PORT(com), 0x03); }
4.3.5 Writing Data to the Serial Port
いよいよデータ本体を serial port に書き込む処理を実装する。チュートリアルのとおりに outb 関数を実装すれば1文字送信できるようになる。一応 write っぽさを出すために以下のように関数を定義してみた。
void serial_write_char(unsigned int com, unsigned char c) { outb(com, c); }
また、serial port の通信の準備をまとめて行うための関数を以下のように定義してみた。
void serial_initialize(unsigned short com) { serial_configure_baud_rate(com, 0x03); serial_configure_FIFO(com); serial_configure_line(com); serial_configure_modem(com); }
ここまでの関数を組み合わせて実際に文字を送信する処理は 4.3.7 章でやってみた。
4.3.6 Configuring Bochs
serial port とホスト側のファイルを関連付けるための設定を追加する。
4.3.7 The Driver
以上のようなシリアルポートへの書き込みを、文字列を引数とする write 関数として作っておくのがよいとのこと。ってことで以下のように logging 関数を作ってみた。serial port との通信は準備をしてからデータを送る流れになる。
void logging(char *buf) { for (unsigned int i = 0; buf[i] != '\0'; i++) { // preparation serial_initialize(SERIAL_COM1_BASE); while (serial_is_transmit_fifo_empty(SERIAL_COM1_BASE) == 0) ; // send data serial_write_char(SERIAL_COM1_BASE, buf[i]); } }
動作確認をするために以下のように logging 関数を呼び出してみる。
logging("os development is fun!\n");
するとログファイルに内容が書き込まれていることを確認できた。
$ cat com1.out os development is fun!
これで今後のデバッグがやりやすくなった。めでたし。
所感
今回はトラブルシューティングにかなりの時間が溶けた。本家チュートリアルのケアレスミスが原因であるものが多いというのが悲しいところ。GitHub にはそれを指摘する issue やプルリクエストが溜まっているので、これらを取り込むだけでチュートリアルとしてのクオリティがかなり上がると思われる。メンテナンス頑張ってほしい。次回はメモリ管理について。楽しそうなのですぐやろう。
【OS自作】littleosbook をやってみる #1
べつに暇なわけじゃないけど、たまには低レイヤなことをしたい。簡易的なオペレーティング・システムの開発方法を解説したサイト The little book about OS development を見つけたのでやってみる。ページは以下。
追記:本家の littleosbook は不備が多いがメンテナンスされてない。以下はフォークされたリポジトリであり、かなりの不備が修正されている。絶対こっち見るほうがオススメ。
作業内容をここにメモって残しておけば、この先10年で3人くらいの役には立つだろう。このチュートリアルはけっこう長いので、ブログ記事としては何回かに分けることになりそう。
簡易的なコンパイラはいくつか作ったことあるけど OS は作ったことない。調べながらやればなんとかなるだろう。ちなみに使用した環境は Ubuntu の 20.04.3。
1 Introduction
導入部分。想定読者のレベルはそこそこ高そう。低レイヤなプログラミングには慣れていないが、まぁなんとかなるだろう。
2 First Steps
さっそくプリミティブな OS を作るところから始まる。
2.1 Tools
環境構築とブートに仕組みについて。x86 用の仮想マシンとして Bochs を使うらしい。
2.2 Booting
BIOS が起動してブートローダが起動する。そしてブートローダが OS のプログラムをロードすることで OS を起動する。ブートローダってちゃんと調べたことないから後で Wikipedia でも読もう。
2.3 Hello Cafebabe
最小の OS を実装する。手順通りに進めてゆく。まずはアセンブリを書いてコンパイルし object file を生成する。そして、実行可能ファイルを生成するために linker script を書いて ld コマンドを実行する。その結果 kernel.elf というファイルが生成される。これが OS カーネルの実行可能ファイルである。
次に、ブートローダである GRUB を入手する。記載されている GitHub 上の URL が誤っている。正しくは ここ にある。OS の実行可能ファイルとブートローダを格納して ISO イメージを作成する。その結果 os.iso というファイルが作成される。
Bochs を使って作成した OS をエミュレータで実行する。ここで実行が上手くいかなかった。どうやら、実行画面を描画するための display library として指定している sdl のインストールが上手くいっていない。準備段階で実行した apt-get install bochs-sdl が上手く機能しないらしい。この問題は以下の issue でも報告されていた。
issue にあるように、この問題は display library として sdl の代わりに X Window System を使うようにすると解決した。具体的には sudo apt-get install bochs-x を実行した後、以下のように Bocks の設定として x を指定した。
megs: 32
display_library: x
(省略)
cpu: count=1, ips=1000000
そして、コマンド bochs -f bochsrc.txt -q を叩くとデバッガが起動する。プロンプトで c コマンドを実行するとエミュレータ画面に何かしらの遷移がある。画面に何が表示されているのかはよく分からない。q コマンドでエミュレータを終了する。実行ログを見ると cafebabe という値が eax レジスタに格納されているようなので上手くいってそう。
$ grep cafebabe bochslog.txt 02120339208i[CPU0 ] | EAX=cafebabe EBX=0002cd80 ECX=00000001 EDX=00000000
3 Getting to C
OS のコードを書くためにアセンブリではなく C 言語を使うための準備をする。
3.1 Setting Up a Stack
C プログラムを実行するためにはスタック領域が必要である。つまり、カーネルプログラムがメモリにロードされた後、カーネルがスタック領域を使って様々な OS の仕事をできるようにする必要がある。そのための領域を確保する。いい加減なやり方としてはメモリにランダムにアクセスして、その周辺をスタック領域として使うやり方である。これは使えるメモリの領域が不明だったり、すでに使われている領域と被ってしまう可能性があるので避けるべき。
そこで今回は、カーネル用に固定した領域を確保する方法を取る。具体的には、未初期化領域を表す bss segment に適当なサイズを確保し、そこをカーネルが使うスタック領域とする。掲載されているコードを loader.s に追加してみた。
3.2 Calling C Code From Assembly
アセンブリから C プログラムを呼び出す方法について。スタックに push してから call すればよい。この先、頻繁に用いるメモリレイアウトがあるらしく構造体を定義したほうがよいとのこと。そこで、以下のようなコードを書いて kmain.c とした。
struct example { unsigned char config; /* bit 0 - 7 */ unsigned short address; /* bit 8 - 23 */ unsigned char index; /* bit 24 - 31 */ } __attribute__((packed)); void kmain() { }
3.3 Compiling C Code
普通の C プログラムをコンパイルするのとカーネルをコンパイルするのでは前提が全然違うので、gcc のオプションを色々付けるとのこと。
3.4 Build Tools
掲載されている通りに Makefile ファイルを作った。すると make run でコンパイルからエミュレータの起動まで一気にできるようになった。これは楽ちん。
所感
パート1はいったんここで終わり。トラブルシューティングなどの必要もあり、調べながら進めたのでここまでの内容はそれなりに分かった。わりと丁寧に書かれたチュートリアルだと思うが、Bochs の実行方法が書かれていなかったり、object file やレジスタに関する基礎知識は前提とされているように感じた。調べながら進めれば問題ない内容にはなっていると思うので大きな問題ではないが。ぼちぼち進めていこう。
3Blue1Brown で学ぶ線形代数
最近は YouTube で数学の解説が上がっていたりする。質の高いコンテンツも多く、独学勢にとってはありがたい時代である。なかでもスゴいのが 3Blue1Brown の動画。チャンネル登録者数400万人も納得のクオリティである。
今回は 3Blue1Brown の線形代数(Linear Algebra)のシリーズを見てみる。何年か前にも見たことあって線形代数の気持ちをかなり理解できた記憶がある。こういうのは何度見ても発見があるのでもう一回見てみる。シリーズの動画は以下。
この記事では、各動画の中で重要そうなところをメモる。
- 0. Essence of linear algebra preview
- 1. Vectors, what even are they?
- 2. Linear combinations, span, and basis vectors
- 3. Linear transformations and matrices
- 4. Matrix multiplication as composition
- 5. Three-dimensional linear transformations
- 6. The determinant
- 7. Inverse matrices, column space and null space
- 8. Nonsquare matrices as transformations between dimensions
- 9. Dot products and duality
- 10. Cross products
- 11. Cross products in the light of linear transformations
- 12. Cramer's rule, explained geometrically
- 13. Change of basis
- 14. Eigenvectors and eigenvalues
- 15. A quick trick for computing eigenvalues
- 16. Abstract vector spaces
- 所感
0. Essence of linear algebra preview
まずはこのシリーズの目的について述べている。線形代数といえば行列計算など計算手順に重きを置いて説明されがちだが、本シリーズは直感な(幾何的な)理解に重きを置いた構成になっているとのこと。
実際、この意図はかなり効果的で、シリーズを通して見ると線形代数の各構成要素がどういう操作に対応しているのか分かるようになる。そういう意味で板書ベースの大学の講義より線形代数の意義を理解しやすい。
1. Vectors, what even are they?
ベクトルの説明について。ベクトルには、ベクトルを足し算する操作とスカラー倍する操作が重要。例を使いながらその直感的な意味を説明している。ここまでは普通の線形代数の導入といった感じ。
2. Linear combinations, span, and basis vectors
単位ベクトルとして x 軸方向の と y 軸方向の
を導入する。これらのベクトルは basis vectors(基底ベクトル)であり、基底ベクトルのスカラー倍の和として任意のベクトルを表現できる。これは基底ベクトルの liner combination(線型結合)と呼ばれる。ただし、基底ベクトル同士が同じ方向を向いていたり、零ベクトルだった場合は、線型結合が任意のベクトルを表現できるわけではない。線型結合で表現できるベクトルの集合を span と呼ぶ。
3. Linear transformations and matrices
行列とベクトルの積についての直感的な説明をしている。
transformation(変換)とはベクトルを入力としてベクトルを出力するものである。ベクトルを動かすと捉えることもできる。任意のベクトルに対する変換を考えるため、座標系に張った格子が変換によってどう変形されるのかを見てみる。さまざまな変換が考えられるが、liner transformation (線形変換)は原点の位置が変わらず、格子の直線が等間隔の直線のままであるような変換である。
ここで線形変換の重要な性質がある。ベクトルを動かすのが変換であったが、線形変換の前後で基底ベクトルを用いた表現は保たれるということである。たとえば、変換前後で以下の関係が成り立つ。
変換前:
変換後:
ここで Transformed は変換後のベクトルを示している。つまり、線形変換によって得られるベクトルを計算するには、それぞれの基底ベクトルがどこに動くのかだけ求めればよい。個々のベクトルの動きを求める代わりに、その空間を張る基底ベクトルの動きを追えばよいということである。
そして、線形代数は行列に対応する。具体的に以下のような行列を考える。
実は、1列目の が変換後の
であり、2列目の
が変換後の
を示している。そのため、この線形変換によってベクトル
がどう変換されるのかは以下のように考えればよい。
\begin{align} \text{Transformed}\ \begin{bmatrix} 5 \\ 7 \end{bmatrix} & = 5 (\text{Transformed}\ \hat{i}) + 7 (\text{Transformed}\ \hat{j}) \\ & = 5 \begin{bmatrix} 3 \\ -2 \end{bmatrix} + 7 \begin{bmatrix} 2 \\ 1 \end{bmatrix} \\ & = \begin{bmatrix} 29 \\ -3 \end{bmatrix} \end{align}
この動画を通して、高校数学でも習う行列計算の意味が理解できる。線形変換では座標系全体(基底ベクトル)を動かしているというイメージが大切。
4. Matrix multiplication as composition
行列と行列の積について説明している。前回の話が理解できていれば、行列と行列の積は線形変換の合成に対応することが分かる。結局のところ、2つの線形変換を通して基底ベクトル と
がどこに移るのか計算しているに過ぎない。
5. Three-dimensional linear transformations
これまで2次元の話を扱っていたが、3次元についてもここで扱う。2次元の場合と同様に、3次元の場合は 3×3 の行列によって線形変換が表現される。
6. The determinant
determinant(行列式)は線形変換ごとに定まる値であり、その線形変換によって平面上の面積が何倍になるかを表す。線形変換では、座標系上のどこにある領域でも変換前後の面積の比が一定であるため、行列式のような定数として計算できる。なお、行列式の値が負になる場合は軸の向きが逆転したことを示す。3次元の場合も同様で、空間上の体積の変化を示す。
行列式の計算方法は色々あるが、それは線形代数の理解には本質的ではないと言っている。100回くらい頷きたい。大学の線形代数の授業はここらへんの手計算に重きを置きすぎなんだよな。
7. Inverse matrices, column space and null space
行列計算の有名な応用として、多元一次方程式を解く方法を例に挙げている。この例を通して、行列の逆行列・column space・ランク・カーネルなどの考え方を紹介。要するに、線形変換を分類する方法として、その結果として得られる空間(column space)が重要だと思えばよさそう。たとえば行列式が0のときは空間が潰れる。
8. Nonsquare matrices as transformations between dimensions
これまで n×n 行列(正方行列)のみ扱って来たが、線形変換はベクトルを動かす操作に対応していた。m×n 行列の場合は、n 次元のベクトルを m 次元のベクトルに変換するような線形変換に対応する。たとえば、 は2次元ベクトルを1次元ベクトルに変換する行列であり、2次元空間の基底ベクトル
,
をそれぞれ 1, 2 に移すような線形変換である。
9. Dot products and duality
ベクトルとベクトルの dot product(内積)についての説明。内積がベクトルの射影を表しているというのはお馴染みの内容。ここで面白いのが、内積と 1×2 行列による線形変換が対応しているという点である。具体的には、ベクトルをあるベクトルの方向について射影する計算と、基底ベクトルを1次元に埋め込む線形変換が対応している。こういう異なるものが対になる関係を duality(双対性)という。
10. Cross products
ベクトルとベクトルの cross product(外積)についての説明。ベクトル ,
の外積
はベクトル
であり、
は
とも
とも垂直かつ、
の大きさは
と
がなす平行四辺形の面積と一致する。この平行四辺形の面積は行列
の行列式として計算できるのであった。
11. Cross products in the light of linear transformations
外積の計算方法とその幾何的な意味について。行列式の値(体積)と外積の結果の整合性が取れていることを確認しているように思われる。この章は内容がややこしいのでスキップ。
12. Cramer's rule, explained geometrically
方程式を解くための Cramer's rule(クラメルの公式)の幾何的な説明。例として、二元一次方程式を次の線形変換 として捉える。
\begin{align} \begin{bmatrix} 2 & -1\\ 0 & 1 \end{bmatrix} \begin{bmatrix} x\\ y \end{bmatrix} = \begin{bmatrix} 4\\ 2 \end{bmatrix} \end{align}
このとき、変換前の と
がなす平行四辺形の面積は
であるため、変換後の面積は
で得られる。ここで
は線形変換
による面積の変化を表していることに注意する。他方、変換後の面積は
と
がなす平行四辺形を考えると以下で計算できる。
\begin{align} \text{det}( \begin{bmatrix} 2 & 4\\ 0 & 2 \end{bmatrix} ) \end{align}
変換後の面積に関するこれら2つの式を等号で並べたのがクラメルの公式である。要するに、変換前後の平行四辺形の面積の関係を考えることが本質と言える。
13. Change of basis
基底ベクトル(座標系)の変換について。Chapter 3 で学んだ通り、線形変換は基底ベクトルを移動することに相当する 。線形変換 によって座標系を変えたら
によって元の座標系に戻せる。つまり、線形変換と逆変換によって座標系を行ったり来たりできる。
のような行列計算を見たら、線形変換
を行うため一時的に座標系を変えていると思えばよい。
14. Eigenvectors and eigenvalues
固有ベクトルと固有値について。線形代数といえばこのあたりの話がややこしい。
線形変換は、格子を平行に保ったまま等間隔に拡大するような操作であった。このとき、ある特別なベクトルは変換前後で方向が変わらない。このようなベクトルを固有ベクトルと呼ぶ。ただし、固有ベクトルの大きさは変化する可能性があり、その倍率を固有ベクトルの固有値と呼ぶ。たとえば、固有値が2であれば固有ベクトルの大きさは変換によって2倍になる。
固有値・固有ベクトルの求め方についても説明がある。これはよくある流れで、 を満たす
が固有ベクトルであり、
が固有値である。
は零ベクトルではないので、この式を満たすためには線形変換
が次元を下げるようなものでないといけない。これは変換後の面積が0になる、つまり行列式が0となる必要がある。よって、
を解くことで固有値が求まる。
これ自体は教科書的な流れだが、線形変換がもつ意味や行列式が0になるときの変換の様子がイメージできているだけで固有ベクトルや固有値が何であるのかよく理解できる。
15. A quick trick for computing eigenvalues
2×2行列の固有値を求める簡単な方法について。テクニック的な話なのであまり重要ではないと思った。
16. Abstract vector spaces
ベクトルや線形変換を一般化した線形空間について。
- Additivity:
- Scaling:
の2つの規則を満たすとき線形性があると言える。線形性のあるものの例として多項式の微分が挙げられている。多項式の微分が線形性を持つのは当たり前だが、微分に対応する線形変換を行列として表現できることを説明しているのが面白い。
所感
久しぶりに線形代数を勉強した。ある操作があるとして、対象を直接操作するときと、対象をいったん分解してそれぞれ操作をした後に合体したときに同じものが得られるというのが線形代数の本質的なところ。この様子を視覚的にイメージできるようになるのがこのシリーズの目的であり、それを達成するのに十分なコンテンツを提供している。大学の授業はこれ見せとけばいい。
Scala UDF を SQL に変換する技術
論文メモ。今日はプログラム合成を用いてプログラムを変換する手法について。
論文
UDF to SQL Translation through Compositional Lazy Inductive Synthesis
OOPSLA2021
https://www.cs.utexas.edu/~isil/clis.pdf (preprint)
論文の概要
データベースシステムが提供する一般的な機能として、ユーザが独自に定義した UDF(user-defined function)を SQL から呼び出す機能がある。UDF は一般的なプログラミング言語で書けるため利便性が高い一方で、実行時に性能に問題が出ることがしばしばある。この問題に対して本論文では UDF をピュアな SQL に自動変換する技術を提案する。本手法の特徴は、あらかじめ定義された変換ルールを適用するルールベースの手法ではない点である。具体的には、lazy inductive synthesis というプログラム合成を用いた新たなアプローチを提案している。
手法の入出力
手法の入力
手法の出力
- SQL クエリ
- ただし
と
は任意の入力に対して同じ出力を返す。
- ただし
データフローグラフ
まずは本手法の前提としてデータフローグラフを簡単に説明する。データフローグラフはプログラム中の変数の定義と使用の関係を示したグラフである。論文中では以下が例として挙げられている。

左がプログラムで、右がデータフローグラフである。データフローグラフの各ノードが命令列であり、各エッジが変数の流れを示している。
ノードの作り方には自由度があり、なるべく多くの命令をまとめて1つのノードとしてもよいし、少ない命令をまとめて1つのノードとしてもよい。ちなみに、一般的なデータフローグラフはループ構造がある場合はループを持つグラフになるが、論文では Direct Acyclic Graph(DAG)であると書かれている。これは cyclic になるようなノードの作り方は許さないという暗黙の前提を意味しているのだと思われる。
本研究では、ノードの分割方法に応じてグラフ同士の順序関係を定義している。より細かくノードを分割しているほど "小さい" ような順序関係になっている。たとえば、以下の2つのグラフ ,
を考える。

このとき は
よりノードを細かく分割しているので
となる。
本手法では、グラフのノードごとに合成を行うアプローチを取る。1つのノードに含まれる命令数が多いほど合成の難易度が高くなるという前提を取っているため、グラフの分割の仕方としては より
のほうが合成の難易度が低いものと考えている。
Counter-Example Guided Inductive Synthesis
Counter-Example Guided Inductive Synthesis(CEGIS)は、段階的に複雑なプログラムを合成してゆく手法である。プログラム合成の研究をしている人にとってはお馴染みのアプローチであり、本手法でも変換前と同値なプログラムを合成するために用いられる。
CEGIS では、有限個の入出力例からプログラムを合成し、そのプログラムが合成の仕様を満たしているか検証する。仕様を満たしている場合は合成に成功した状況なのでおしまい。一方で仕様を満たしていない場合は、検証結果として反例が与えられるので、それを有限個の入出力例に追加することで満たすべき入出力例を精緻化する。このように合成と検証(と反例の生成)を繰り返すことで仕様を満たすプログラムを合成するアプローチである。
本手法では、変換前と同値なプログラムを合成することが目的である。そのため合成問題の仕様は「変換前のプログラムと同値であること」となる。したがって CEGIS においてプログラムの同値性を検証する必要があるが、そのために既存のモデル検査器(Clarke et al., 2004)を用いている。この検査器は C 言語で書かれたプログラムの同値性を検証するものであるため、変換前後のそれぞれのプログラムを C 言語のプログラムに変換しておく必要がある。この C 言語への変換処理は著者らが実装したとのこと。
入出力例からの SQL の合成には Trinty(Martins et al., 2019) というプログラム合成のフレームワークを用いており、73個の SQL の命令をもつ DSL を独自に定義することで合成を行っている。使用する定数の探索空間は、整数なら 1, 0, -1 などよく使われそうなもののみを用いるようにしている。
手法のアプローチ
本手法の合成アルゴリズムについて説明する。まずは、変換元となるプログラムからデータフローグラフを構築する。このときノードの分割方法はいろいろあるが、分割方法が細かいものから順に合成の対象とする。そしてデータフローグラフのノードごとに合成を行う。具体的には、各ノードに入ってくる辺を入力変数、ノードから出ていく辺を出力変数と見なしたうえで CEGIS として合成を行う。つまり元の Scala の命令列に対応する処理を SQL の命令列として合成することになる。CEGIS では、合成結果として得られたプログラムと、元の命令列が同値であるかを検証する。すべてのノードに対して合成に成功すればおしまい。一方で合成に失敗した場合は、より粗いノードの分割をもつデータフローグラフを対象に合成を試みる。以降、この流れをすべてのノードにおいて合成が成功するまで繰り返す。
細かいノードの分割からスタートして徐々に粗い分割を対象としていく流れが独自性が高い部分であり、本手法の貢献となっている。必要に応じて合成を行うという点から著者らはこのアプローチを lazy inductive synthesis と呼んでいる。
評価実験
Github からランダムに抽出した Scala の UDF に対して実験を行った。人手での調査によると100件のうち63件が UDF を除去できることが分かった。本手法を用いることで、63件のうち58件において UDF を除去できた。
所感
- inductive program synthesis を用いた変換手法という点が新しくて面白い。スクラップ&ビルドという感じ。
- 本手法では Scala のシーケンシャルな命令列を SQL の命令に置き換えることが狙いといえる。先行研究はカーソルループを用いた集約計算を SQL 化することに重きを置いたものが多いが、本手法では集約計算はサポートされていない。この点おいて、ルールベースではないことの強みを生かしきれてない印象を受けた。(変換ルールを定義することが本質的に難しいのは集約計算のような処理だと思うので。)
- 評価実験の結果はかなり素晴らしいように見える。UDF をピュアな SQL に変換できるのは、そもそもユーザが「Scala では使うべき関数が分かるけど SQL ではどの命令を使えばよいか分からない」みたいな状況のときにUDF を使うからなのかな。つまり SQL を書くにあたって構文的な難しさがあるというより、単に SQL の命令を知らないことが主な原因な気がした。もしそうならルールベースで命令の対応関係を大量に作ってあげるだけで、実はかなりの精度が出るのかもしれない。
PyTorch の Transformer に入門する
PyTorch の公式チュートリアルに Transformer を使ったテキスト処理の章がある。これが何やってるのか分からん。もちろん Transformer の仕組みは分からん。それは想定内。問題は Transformer の外側で何をやってるのか分からんってこと。今回はそれを解説しようと思う。
問題のチュートリアルは以下である。例によって、本記事に載っているソースコードはこのチュートリアルからの引用である。
以降では、このチュートリアルのソースコードを使ったまま、このチュートリアルが何をやりたいのかを解説する。説明の順序はオリジナルからかなり変えている。そして本記事では Transformer の仕組みについては解説しない。
データセットの読み込み
まずは学習に用いるデータセットを読み込む部分から説明する。その後 Transformer に入力するためのテンソルへ変換する部分を理解しよう。
以下のように data_process 関数が定義されている。これはデータセットのイテレータをベクトルに直す関数である。
def data_process(raw_text_iter: dataset.IterableDataset) -> Tensor: """Converts raw text into a flat Tensor.""" data = [torch.tensor(vocab(tokenizer(item)), dtype=torch.long) for item in raw_text_iter] return torch.cat(tuple(filter(lambda t: t.numel() > 0, data)))
この関数の data = の右辺の操作が何をやっているのか分かりづらいので、以下のように for 文で書き直してイテレータの要素がどんなベクトルに変換されるのか見てみた。
train_iter, _, _ = WikiText2() for str in train_iter: print("str=", str) tokens = tokenizer(str) print("tokens=", tokens) vocabs = vocab(tokens) print("vocabs=", vocabs) print("tensor=", torch.tensor(vocabs, dtype=torch.long)) # -> (以下は実行結果) ... str= = Valkyria Chronicles III = tokens= ['=', 'valkyria', 'chronicles', 'iii', '='] vocabs= [9, 3849, 3869, 881, 9] tensor= tensor([ 9, 3849, 3869, 881, 9]) ...
イテレータから取り出した1文を単語ごと(tokens)に分割し、単語ごとに対応する整数値(vocabs)に変換する。そして、それを要素にもつテンソルが出来上がる。上記の例では5単語なので長さ5の1次元テンソル(ベクトル)に変換されている。つまり1文をベクトルにエンコードする処理である。
data_process 関数内では、この処理が イテレータに含まれる各文に対して行われ、得られたベクトル同士が結合される。プログラミングが得意な人に向けて言うと、data_process 関数は入力されたイテレータに対して flatMap を行うイメージである。
以上の話を踏まえると、以下では各イテレータが長いベクトルに変換されることが分かる。
train_iter, val_iter, test_iter = WikiText2() train_data = data_process(train_iter) val_data = data_process(val_iter) test_data = data_process(test_iter)
バッチへの分割
次に、Transformer の入力として適当な形にするため、得られた長いベクトルを適当に分割してバッチ化する。この処理を行うのが batchify 関数である。
この処理の様子は公式チュートリアルに載っている以下の図がとても分かりやすい。以下の例では左辺が長いベクトルで、右辺がバッチ化されたテンソルである。バッチサイズが4であるときの例であるため、テンソルには4つの要素が存在している。つまりバッチサイズとは「何個のバッチを作るか」のことである。

ここで注意点がある。バッチ化をする batchify 関数であるが、上記の図のバッチを作ったあとにしれっと t() という関数呼び出しで テンソルの0次元と1次元を入れ替えている。つまり、batchify 関数が返すものはバッチ分割しただけのものではない。これがめっちゃ紛らわしい。正しくは以下の図が batchify 関数の正しい挙動である。

この図をイメージすると、以下の batchify でどんな処理が行われているのか理解しやすいだろう。たとえば train_data というベクトルは20個のバッチに分割された後、各バッチの i 番目の要素が1つのベクトルにまとめられる。
batch_size = 20 eval_batch_size = 10 train_data = batchify(train_data, batch_size) # shape [seq_len, batch_size] val_data = batchify(val_data, eval_batch_size) test_data = batchify(test_data, eval_batch_size)
入力データとターゲットの作成
ここからは Transformer に入力するための "入力データ" と、その結果の正しさを検証するための "ターゲット" データを作成してゆく。このペアは get_batch 関数によって得られる。公式チュートリアルに載っている以下の図を見てみよう。

この図に例では i=0 かつ bptt=2 であるため、Input として0番目からの2行が抽出されている。Target は Input の行を1つだけずらしたものである。
この Input と Target の意味を説明する。Transformer は、文中のある単語の次に出現する単語を予測するモデルである。Transformer は Input の各要素に対して「次に出現する単語」を推定する。図の例では、Input の "A" を見たときに「次に "B" が来ること」を予想できることが望ましい。(なぜなら実際に "A" に続くのは "B" であるため。)そういう意味で、Target の "B" が Input の ”A" と同じ左上の位置に配置されている。Input の各要素に対する推定の正解が Target の同じ位置に配置されているというわけである。
また、Transformer は文脈を考慮して次に出現する単語を推定する。どれだけの長さの文脈を考慮するかを決めるのが bptt というパラメータである。図の例では bptt=2 であるため直前の単語のみ考慮される。たとえば、Input の "H" に対して次の単語を予想するときは直前に "G" が来たことを考慮する。これを考慮した上で、正解の "I" が推定できるかという話である。
モデルの実行
Transformer を学習するときも評価するときも、上記で作成した入力データ(テンソル)をモデルに与えて実行することになる。ということで Transformer のモデルを実行する部分を見ていこう。
例えば以下のようにモデルを実行してみる。モデルの実行にはバッチが必要なので、テキストを単語分割したあとにバッチ化している。
original_text = "The capital of Japan is Tokyo." data = torch.tensor([vocab(tokenizer(original_text))]).t().to(device) src_mask = generate_square_subsequent_mask(len(data)).to(device) output = best_model(data, src_mask)
ここでは data という入力データを作成し model に与えている。加えて、 src_mask というものがモデルに与えられている。これは次に出現する単語の先読みを許さないようにするものらしいが詳しいことは分からない。とにかくTransformer を正しく動かすために必要な引数だと思っておく。
モデルの出力である output はやや複雑な構造を持っている。上での述べたとおり、Transformer は次に出現する単語を推定するものである。具体的には、辞書に含まれる各単語に対して、次の単語として出現する確率を割り当てる。例えば、利用可能な単語が10個であったとき、1つ目の単語に5%、2つ目の単語に8%、3つ目の単語に14%、... といった感じである。このチュートリアルの単語数は28,782個らしいので、かなり選択肢の多い確率分布を推定することになる。
では output の構造について見ていこう。入力データである data の shape もついでに見てみる。
print(data.shape) print(output.shape) # -> (以下は実行結果) torch.Size([6, 1]) torch.Size([6, 1, 28782])
入力データの data の shape は [6, 1] である。これは6単語からなるデータであることを意味する。そして、モデルの出力である output の shape は [6, 1, 28782] である。すべての単語数が28,782個であることを思い出すと、これは入力データの各単語ごとに「次に来そうな単語」を予想し、それを確率分布として保持しているのである。
実際に、次にどんな単語が来ると推定されたのか見てみよう。入力の各単語ごとに、確率分布のうち最大値をもつ単語を表示してみる。
for i, e in enumerate(output): max_index = torch.argmax(e[0]) print(vocab.lookup_token(data[i][0]), "->", vocab.lookup_token(max_index)) # -> (以下は実行結果) the -> first capital -> of of -> the japan -> , is -> a tokyo -> ,
結果として「capital の後に of が来る」という予想しか当たっていない。残念。このチュートリアルのような手軽な学習ではこんな感じのよく分からない推定結果になっているが、Transformer そのものはすごいものなんだろう。
ここまで分かれば、学習や評価で具体的に何が行われているのかソースコードを読めば分かると思われる。めでたし。
所感
結局のところ、公式チュートリアルは batchify の図があまりに紛らわしい。それと get_batch 関数の出力の意味について説明が足りてない。なぜあんなデータ構造にするのか初学者には分からん。ついでに、学習済みの Transformer を使って実際に単語を予測してみる例がないので、全体を通して何を作っているのか分かりづらい。満足な精度が出ないから載せてないのかもしれないが、何を出力するものか分からずに精度が改善されてゆく様子だけ見せられてもよく分からん。
次は Transformer そのものや mask が何だったのか調べてみよう。
PyTorch の自動微分に入門する
前回 は PyTorch のチュートリアルの最初だけやってみた。そこで PyTroch の自動微分の概念が重要であることが分かったので、今回は自動微分のチュートリアルをやってみる。ページは以下。
忘れてはいけないのは PyTorch のテンソルはお化けオブジェクトであるということ。どんな情報を持っていてもおかしくない。そこに惑わされないように今回も気をつけよう。例によって、本記事で記載するソースコードや図は上記のチュートリアルからの引用である。
Automatic Differentiation
このチュートリアルは以下のプログラムについて扱っている。テンソルをたくさん作って計算している。
import torch x = torch.ones(5) # input tensor y = torch.zeros(3) # expected output w = torch.randn(5, 3, requires_grad=True) b = torch.randn(3, requires_grad=True) z = torch.matmul(x, w)+b loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
重要なポイントは、このプログラムは単にテンソルの計算するだけでなく、計算グラフ(computation graph)を構築している点。以下のようなグラフが構築されると考えればよいらしい。
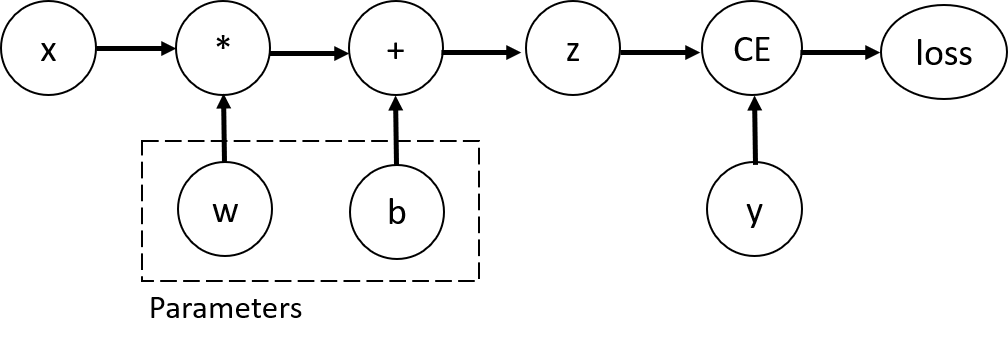
このグラフのノードがテンソルを表しており、エッジは各テンソルがどのテンソルをもとに計算されているのかを表している。もちろんテンソルに対する任意の演算が計算グラフ上で表現できるとは限らず、その演算が torch.autograd.Function クラスのインスタンスになっている必要がある。
図中の Parameters と書かれている部分は最適化の対象となるパラメータであり、プログラム中では requires_grad=True を指定することで表現される。ちなみに、バックプロパゲーションにより勾配計算が伝播されるので、実際はグラフのノード同士は単方向ではなく双方向につながっていることが予想される。
そして、最終的な誤差を計算グラフ上に伝播させることで各パラメータの勾配を求める。以下のコードで実行できる。
loss.backward() print(w.grad) print(b.grad)
当たり前だが、勾配が求まるのはパラメータだけであり、x などの学習データのテンソルの勾配が計算されるわけではない。パラメータは requires_grad=True が指定されたテンソルであり、この世界では特別な存在だと思ったほうがよさそう。
ここまでの話で、テンソルの計算をしていると見せかけて裏ではグラフが構築されることがわかった。PyMC3 とかの確率的プログラミングに似ている印象を受ける。確率的プログラミングでは確率変数の計算をプログラム上で記述すると、裏では対応するベイジアンネットワークが構築される。そんな感じ。
実験してみる
要するに、テンソル演算の偏微分をもとに勾配を計算できるわけだ。ってことで簡単な例を用いて実際に勾配を計算してみる。
ここでは2次関数の勾配を求めている。具体的には、2次関数 の
における傾きを求めてみる。あらかじめ手計算で答えを求めておくと、
なので
における傾きは 6 である。
これを PyTorch のプログラムとして表現すると以下のようになる。
x = torch.Tensor([3]) x.requires_grad_(True) y = x * x + 1 y.backward()
得られた x の勾配を見てみると、確かに 6 が得られていることが分かる。
print(x.grad) # -> tensor([6.])
ニューラルネットワークというのは一種の計算グラフを表しているに過ぎない。勾配計算の逆伝播がニューラルネットワークの構成要素に対してできるようになっているので、PyTorch のユーザは部品を組み合わせてニューラルネットワークを定義するだけでパラメータの最適化を実行できるというわけである。
optimizer と loss はどう関係しているのか?
ここで 前回の記事 の疑問に戻ってくる。以下のようなプログラムでパラメータを更新できるのが気持ち悪いのであった。特に optimizer と loss の間のデータフローがよく分からなかった。
model = NeuralNetwork().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
...
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
今になってみるとそれなりに仕組みが分かるぞ。loss.backward() によって、 loss を求めるために必要な各テンソルの勾配が計算される。裏では計算グラフ上で勾配の伝播計算が走っていると思えばよさそう。model のパラメータとなるテンソルは裏では requires_grad=True になっているんだろう。そして optimizer はそれらのテンソルへの参照を保持している。そのため、loss.backward() で計算された勾配を使って optimizer がパラメータの更新を行えるという仕組みなんだろう。
所感
これで PyTorch の チュートリアル に載っていたプログラムを一通り理解できた気がする。裏では計算グラフが構築され勾配計算が行われることもイメージできた。おまけに計算グラフの構築方法とそれを用いた自動微分の仕組みがあることも分かった。かなり汎用的な仕組みなので今後の役に立ちそう。
PyTorch に入門する
論文とかに載ってるニューラルネットワークのアーキテクチャを再現して自由自在にカスタマイズできるようになりたい。最近はニューラルネットワーク触るとなると PyTorch らしい。ってことで PyTorch のチュートリアルやってみる。チュートリアルのページは以下。
ニューラルネットワークの学習を理解するために重要な確率的勾配降下法と誤差逆伝播法については以前の記事で解説を書いた。
これらの概念はしっかり理解しているつもりなので、PyTorch というフレームワーク上でどう表現されているのかを見ていきたい。なお、本記事のソースコードはすべてこのチュートリアルからの引用である。
0章 Quickstart
まずは全体像を学ぶ章から見てゆく。
PyTorch でデータ扱うには以下の2つが重要らしい。
torch.utils.data.Dataset- サンプルとラベルからなるデータ
torch.utils.data.DataLoaderDatasetをイテラブルにしたデータ
以下のように Dataset を DataLoader に変換できる。このときバッチサイズを指定することで、1回のイテレーションでそのバッチサイズだけのデータが取得できる。
batch_size = 64 # Create data loaders. train_dataloader = DataLoader(training_data, batch_size) test_dataloader = DataLoader(test_data, batch_size) for X, y in test_dataloader: print("Shape of X [N, C, H, W]: ", X.shape) print("Shape of y: ", y.shape, y.dtype) break
モデルを定義するときは以下のように nn.Module というクラスを継承するらしい。そして、__init__ 関数内にニューラルネットワークのレイヤーを定義して、forward 関数内にデータがどう受け渡されてゆくのか定義する。
class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() self.liner_relu_stack = nn.Sequential( nn.Linear(28*28, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 18), ) def forward(self, x): x = self.flatten(x) logits = self.liner_relu_stack(x) return logits
そして、学習時に用いる損失関数やオプティマイザを設定する。今回の例ではクロスエントロピーと確率的勾配降下法を指定している。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
あとは学習データの各バッチを読み込みながらパラメータを調整してゆく。バックプロパゲーションは以下のような記述をするらしい。
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
学習の流れの雰囲気は掴めた。要するにデータを用意してモデルを定義して学習を実行すればオッケー。
疑問点を解消してゆく
次は "1章 Tensors" なので次はテンソルについて学んでいこう。...と言いたいところだが上記の確認だけで雰囲気が分かってしまったので、ここからは自分が抱いた疑問点を解消しながら理解を深めていきたい。
学習モデルのインスタンス変数はなぜ必要か?
独自のモデルを定義するときは nn.Module を継承するのであった。このとき、__init__ 関数内でインスタンス変数(self でアクセスする変数)を定義している。
def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() self.liner_relu_stack = nn.Sequential(...) def forward(self, x): x = self.flatten(x) logits = self.liner_relu_stack(x) return logits
しかし、これらのインスタンス変数は forward 関数でしか使われない。だったらなぜインスタンス変数として定義するのか。以下のように forward 関数内に記述すればよいのでは?
def __init__(self): super(NeuralNetwork, self).__init__() def forward(self, x): x = nn.Flatten(x) logits = nn.Sequential(...)(x) return logits
しかし実際にこのコードを実行してみると以下のようなエラーメッセージが表示される。
ValueError: optimizer got an empty parameter list
オプティマイザに渡すモデルのパラメータが空であると怒っている。学習によって調整するパラメータはモデルのインスタンス変数として定義されていなければならないのか。理解した。考えてみれば、モデルのオブジェクトが調整されるべきパラメータの情報を持っているっていうのは直感的で分かりやすい。
Flatten 関数とは何か?
モデルを定義するときに nn.Flatten() という関数が使われている。おそらくテンソルを1次元ベクトルに直す関数だと予想されるが念のため調べる。
どうやら引数に与えられた範囲の次元を1つのテンソルにするということらしい。つまり常にベクトル(1次元テンソル)を返すとは限らない。ちょっと実験してみよう。
まずはデフォルトの start_dim = 1 の場合に2次元のテンソルを与える。
t = torch.Tensor([[1,2],[3,4],[5,6]]) nn.Flatten()(t) # => tensor([[1., 2.], [3., 4.], [5., 6.]])
2次元以降はすでに1つのテンソルなので、もちろん何も変化がない。
次は同じ条件で3次元のテンソルを与えてみる。
t = torch.Tensor([[[1,1],[2,2]],[[3,3],[4,4]]]) nn.Flatten()(t) # => tensor([[1., 1., 2., 2.], [3., 3., 4., 4.]])
今度は1次元の構造はそのままで2次元以降が flatten されていることを確認できた。
なぜ nn.flatten の引数の start_dim のデフォルト値が 1 であるのか。それは、1つの学習データは1つのテンソルに対応するため、1つのバッチは複数のテンソルに対応するからである。たとえば、バッチサイズが64である場合はバッチは以下の次元をもつ。
for X, y in train_dataloader: print(X.shape) # => torch.Size([64, 1, 28, 28])
flatten 関数がこのように挙動するおかげで、forward 関数を実行するときにバッチごと入力できて、その出力を1つのテンソルとして返せる。以下はその例である。
for X, y in train_dataloader: print(X.shape) print(nn.Flatten()(X).shape) print(model.forward(X.to(device)).shape) # => torch.Size([64, 1, 28, 28]) torch.Size([64, 784]) torch.Size([64, 18])
flatten の処理だけでなく forward 関数の動きにもイメージが湧いた。
train 関数ってなに?
モデルの学習を行うところで以下のように model.train() という謎の呼び出しがある。パラメータの更新は for ループの中でやっているのに、なぜループの外にこんな呼び出しがあるんだろう。
def train(dataloader, model, loss_fn, optimizer): size = len(dataloader.dataset) model.train() for batch, (X, y) in enumerate(dataloader): ...
公式ドキュメント を見てみるとnn.Module の中に train(mode=True) という関数についての説明がある。どうやらモデルには training mode と evaluation mode というのがあって、モジュールによってはこの値が影響するらしい。今から学習しますよ、って意味での model.train() というわけか。ちなみに test 関数の中には model.eval() という呼び出しがある。これは evaluation mode であることを明示している。今回の例ではこれらをコメントアウトしても挙動に変化がなかったので今は気にしなくてよさそう。おそらく発展的な機能。
パラメータの更新はどういう流れ?
おそらく誰にとっても一番よく分からないところ。以下のバックプロパゲーションの処理を記述したコードを再掲する。3行あって3行ともよく分からない。
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
さすがに意味不明なのでチュートリアルの Optimization の章 を見てみる。以下のような記述がある。
Call
optimizer.zero_grad()to reset the gradients of model parameters. Gradients by default add up; to prevent double-counting, we explicitly zero them at each iteration.
optimizer.zero_grad() の呼び出しは勾配をリセットする役割があるらしい。勾配は累積してゆくのがデフォルトの仕様なので、パラメータを更新するたびにゼロにする必要があるってことらしい。なぜ累積されるのがデフォルトなのかよく分からんがこういうものなんだろう。
Backpropagate the prediction loss with a call to
loss.backwards(). PyTorch deposits the gradients of the loss w.r.t. each parameter.
loss.backward() の呼び出しによって誤差を逆伝播させる。これはニューラルネットワークの各パラメータの勾配を計算しているのだと思われる。
Once we have our gradients, we call
optimizer.step()to adjust the parameters by the gradients collected in the backward pass.
optimizer.step() の呼び出しによってパラメータの更新を行う。今回は SGD(確率的勾配降下法)を用いているので勾配に学習率をかけてパラメータの更新を行っているはず。
この処理の流れは直感的である。しかし次の疑問が湧いてくる。
optimizer と loss はどう関係している?
ここで気持ち悪いのが optimizer と loss が独立した変数ではないという点である。とくに loss.backward() の結果が optimizer.step() で使われるという部分のデータフローがどうなっているのか意味不明。変数の依存関係を考えるためこれらの変数の初期化部分などを見てみる。関連しそうな部分を以下に抽出した。
model = NeuralNetwork().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
...
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
optimizer はモデルのパラメータの更新を管理してそう。現在のパラメータの値と更新式を保持していると考えるのが妥当だろう。そして loss は誤差だけ持っていそう。やはりこの2つの変数間でどうデータがやりとりされているのか分からない。そもそも loss.backward() でモデルのパラメータの情報が必要そうだが、モデルの情報を知っているようには見えない。
もっと深堀りして調べてみよう。まさに同じ疑問が Stack Overflow に投稿されていた。気になるよなやっぱり。
この回答によると話はなかなか複雑らしい。ちょっと抜き出すと this Tensor object has a grad_fn prop in which there stores tensors it is derived from. とか言っている。つまり、Tensor オブジェクトは生みの親を覚えているらしい。それなら納得できないことはない。たとえば、 loss はただのテンソルではなく、その誤差を生み出した原因となるテンソル(パラメータの重み)を知っているので勾配の伝播ができるみたいな話だと思われる。これが PyTorch の自動微分の仕組みに関係しているらしく、以下のチュートリアルが参考として与えられている。
このチュートリアルは次の機会にやってみよう。現時点での正確な理解は断念。
所感
今回は初めて PyTorch を触ってみた。けっこう直感的に使える気がする。PyTorch のテンソルがお化けオブジェクトというイメージが湧いた。油断してはいけない。たぶんだけどテンソル経由で様々な情報がやりとりされている。しかしなんでこんな設計にしたんだろう。Python 好きな人にとってはデータフローが隠蔽されることは別にイヤじゃないのかな。分からん。Java のコード読むほうが10倍くらい楽だ。
追記:以下の記事で PyTorch の自動微分の仕組みを勉強してみた。この記事の疑問がそれなりに解消できた。